Sander Klous (KPMG): “Pas lessen uit de wetenschap toe op het bedrijfsleven”

Verslag van Big Data-Driven Decisions-event op Nyenrode University
Eén autodidact, één MSc en drie PhD’s praatten ons op 24 april op Nyenrode Business University bij over 'Big Data-gedreven beslissingen'. Hoe gaat big data onze wereld veranderen? Is big data ook voor mij? Wat voor data en wat voor analyses heb je nodig om datagedreven beslissingen te kunnen maken? Vragen waar iedereen – en zeker marketeers – deze avond antwoord op kregen. Na het eerste deel van het verslag, over de presentatie van Sander Duivestein, dit keer aandacht voor de presentatie van Sander Klous van KPMG.
Sander Klous (@sanderklous) werkt bij KMPG – samen met een team van voormalig collega’s van CERN – om zijn kennis van big data-technieken uit de hoge energiefysica toe te passen ten behoeve van betere bedrijfsvoering en een betere wereld. Zijn claim to fame: experimenten in de Large Hadron Collider, die tot wel 60 TB per seconde aan data genereert. Deze hoeveelheden data heeft hij nog niet gezien bij bedrijven…
Inzicht uit (big) data is nog geen actie
Zijn oprechte behoefte de wereld te verbeteren blijkt wel uit zijn frustratie om de disconnect tussen data en actie: waarom zouden we opeens zoveel verwachten van Big Data, als er al genoeg voorbeelden zijn van inzichten uit small data, waar we helemaal niets mee doen:
-
Ondanks alle media-aandacht weet 90% van de mensen Afghanistan niet aan te wijzen op een kaart van het Midden-Oosten.
-
We weten dat roken slecht voor ons is… toch roken mensen nog steeds.
-
We weten inmiddels hoe slecht ontbossing en broeikasgassen zijn voor ons leefklimaat.
-
We hebben eindeloos veel data over de aandelenbeurzen, maar toch zijn we niet in staat beurscrashes te voorspellen of te voorkomen.

Dit geeft inderdaad te denken…
Zelfs áls big data zijn belofte gaat waarmaken en onverwachte nieuwe waardevolle inzichten gaat opleveren, gaan we hier dan ook iets mee dóen?
De DIKW-pyramide die Sander Duivestein al aanhaalde, mist dus ergens een manier om naar het volgende niveau (van kennis naar wijsheid) te stijgen!
4 big data-uitdagingen
Onze generatie is de eerste én de laatste die last heeft van informatiestress. Vroeger was de wereld klein en overzichtelijk. Je verkreeg je informatie via familie, vrienden en leraren die – naar je aannam – het beste met je voor hadden. In de toekomst zal er zoveel data zijn, dat het gebruik van slimme algoritmes om je te “beschermen” tegen data overload de normaalste zaak van de wereld zullen zijn. Onze generatie zit precies tussen deze twee tijdperken in: aan ons de uitdaging om de juiste informatie te verzamelen en de rest te negeren!
Het probleem van data-overload is één van de uitdagingen die horen bij het vraagstuk “Hoe creëer ik een duurzame informatiemaatschappij?”. Volgens Sander Klous staan we daarnaast voor nóg 4 (big) data gerelateerde uitdagingen.
1. Het creëeren van een duurzame informatiemaatschappij
Maatschappelijke ontwikkelingen waar je met data/informatie op in moet spelen:
-
De groei van de bevolking in verschillende delen van de wereld is in onbalans.
-
Er is sprake van resource contraints (fossiele bronnen, voedsel).
-
We hebben te maken met data overload.
-
Er geldt een onevenredige verdeling van rijkdom.
2. Hoe de rechten en privacy van individuen te garanderen
De huidige privacy-wetgeving is geschreven met klantenkaarten, tijdschriftabonnementen en telefoonboeken in gedachten en daarmee achterhaald. Het CBP is volledig overwerkt en daardoor geen aanspreekpunt meer voor vragen over data en privacy (je moet ze een brief sturen!). Er komt echter steeds meer jurisprudentie: zorg dat je je data-gebruik juridisch zo goed mogelijk regelt.
Waar ligt de grens van de privacy? Het CPB kan je niet helpen. Aangezien de wetgeving hopeloos achterloopt en het volledig juridisch afdekken van je data-gebruik (financieel) onhaalbaar is, heeft Klous een goede richtlijn:
-
Wees bezig met de publieke opinie van wat je onderneemt.
-
Stel jezelf bewust de vraag: “Hoe creëer ik maatschappelijke waarde met big data?”
Deze variant van Google’s “Don’t be evil” lijkt me inderdaad belangrijk: bij het verbinden van databronnen zijn er altijd wel mogelijkheden om “analyses op of over het randje van de privacy” te doen. Door bewust bezig te zijn met de maatschappelijke waarde bij big data-projecten houd je jezelf op het rechte pad en kun je bij eventuele juridische geschillen je aanklager – en jezelf – recht in de ogen kijken.
Maatschappelijke waarde: twee location-based voorbeelden
Sander Klous laat twee aansprekende voorbeelden zien van analyses met een locatiecomponent. Het eerste voorbeeld was een time lapse-visualisatie van tweets met de hashtag “#projectX” op de kaart van Nederland, waarin goed te zien was dat de rellen dagen van tevoren te voorspellen waren geweest: door het hele land werd er in groten getale over getweet.
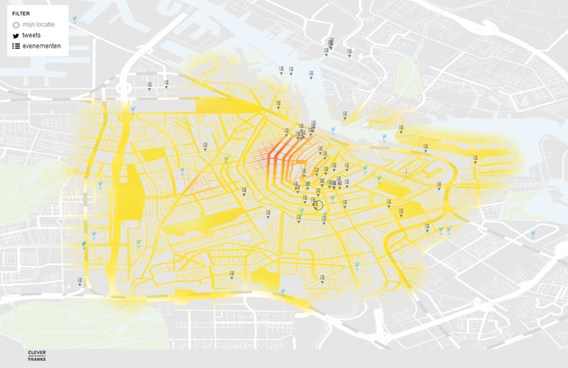
Het tweede voorbeeld was een door KPMG ontwikkelde event/crowdmanagement-applicatie die is gebruikt tijdens de afgelopen Gay Pride en Koninginnedag: op basis van het aantal mobiele telefoons wordt op een kaart van Amsterdam gevisualiseerd waar de meeste mensen zich ophouden en in welke richting zij zich bewegen: een zeer bruikbare tool voor veiligheidsdiensten en politie om op tijd overcrowding te signaleren en voor de efficiëntere inzet van personeel en middelen. Daarnaast kan de koppeling met diensten als Partyflock of Twitter interessante gebeurtenissen in kaart brengen en automatisch het ondersheid maken tussen optredens en ongelukken.
Voorbeeld van koppeling openbare bronnen met eigen verkoopdata
Een ander voorbeeld van een analyse waar bewust is gekozen om aan de veilige kant van de grens van de privacy te blijven, is een project waarbij Klous in opdracht van een bank de adressen in de hypothekenportefeuille koppelde aan de informatie op Funda. Hierdoor kon hij de bank – op basis van vraagprijs van een huis op een bepaald adres op Funda – ruim van tevoren aangeven dat er een groot aantal huizen met zekerheid met restschuld verkocht zou gaan worden en de risicoblootstelling op de volledige hypotheekportefeuille in kaart brengen.
Deze analyse op data van Funda werd vervolgens uitgebreid met een onderbouwde voorspelling van het aantal huizen in de hypotheekportefeuille dat naar verwachting in de komende 3 maanden te koop aangeboden zal worden, op basis van een historische analyse van de (verdeling van) de gemiddelde looptijd van een hypotheek (woontijd in huis). De bank kon op basis van deze analyses tijdig bepalen of ze nog werkten met veilige marges.
Wat in dit voorbeeld wel had gekúnd, maar bewust niet is gedaan, is de bank contact op laten nemen met de huiseigenaren van de op Funda aangetroffen woningen met een vraagprijs ver onder de hypotheekschuld.
3. Hoe als organisatie op juiste manier gebruik te maken van alle beschikbare bronnen
Bovenstaande analyses zijn de eerste stapjes op het gebied van datagedreven werken en voorspellingen doen op data die al binnen organisaties beschikbaar is.
Bestaande (grote) bedrijven hebben een organisatiestructuur die niet geschikt is voor het doen van dergelijke 'ontzuilde' en agile big data-analyses. Pas als de organisatiestructuur wordt aangepast, kunnen er resultaten geboekt worden met big data.
Vanuit KMPG is Sander met een team beziggeweest de organisatiestructuur van het ATLAS-team bij CERN te op te bouwen naast de bestaande structuur, met spectaculaire resultaten: scrums van 2 dagen ipv 2 weken!

4. Het ontwikkelen van kennis en talent voor deze nieuwe discipline
De mensen die dit kunnen hebben een bijzondere skill-set nodig. Er blijkt een match tussen natuurkundigen bij CERN: ze hebben ervaring met het doen van analyses omdat ze iets specifiek te weten willen komen (hypothesegedreven i.p.v. het doen van analyses-voor-het-analyseren).
Mensen met zowel goede analyseskills, kennis van statistiek als communicatievaardigheden (om te kunnen communiceren met de business) zijn schaars: hiervoor is een belangrijke rol weggelegd voor de overheid. Het tekort aan zogenaamde data scientists zal op korte termijn groot zijn, maar op langere termijn zullen betere, gebruiksvriendelijke tools, omscholing van BI-analisten en nieuwe opleidingen een groot deel van dit tekort zullen opvangen.
De belangrijkste managementbeslissingen worden op dit moment nog teveel gemaakt op basis van onderbuikgevoel.
Maatschappelijke dilemma's oplossen met big data-analyses
De lezing van Sander Klous gaf een goed beeld van de maatschappelijke dilemma’s en bedrijfsvraagstukken die opgelost kunnen worden met big data-analyses, -werkwijzen en -organisatiestructuren. Ook gaf hij duidelijke voorbeelden van big data-analyses waar bewust aan de veilige kant van de privacywet werd gebleven en dus géén gebruik is gemaakt van alle mogelijkheden die het verbinden van verschillende databronnen mogelijk maakt.
Big data beoefenen komt dus met een enorme potentiële waarde, maar ook met een grote maatschappelijke verantwoordelijkheid!
Video en slides
Onderstaand vind je de videoregistratie en slides van Sander Klous' presentatie.
Credits afbeelding: Erik Jansen Fotografie
Analyse- en optimalisatie expert bij Online Dialogue.
Plaats reactie
Je moet ingelogd zijn op om een reactie te plaatsen.