Lucky me! Een recept voor succes

Kijken we als consument om ons heen, dan lijken veel producten alsmaar meer op elkaar. Denk maar eens aan consumentenelektronica zoals televisies, of de blauwe spijkerbroek van verschillende jeansmerken. Juist als producten veel op elkaar lijken, zullen ze overkomen als gelijkwaardig en even aantrekkelijk. Wat bepaalt het succes van een product op een markt bestaande uit even aantrekkelijke alternatieven? Wat is een mogelijk recept voor succes?
Stel: Marketingfacts prikt een datum waarop het vijf nieuwe blogposts wil posten. Deze vijf posts vertonen inhoudelijk grote overeenkomsten. Voordat het Marketingfacts-team ze echter plaatst, besluit het eerst een onderzoek te doen. In dit onderzoek beoordelen zo’n duizend vaste Marketingfacts-bezoekers afzonderlijk van elkaar de inhoud van de blogposts op aantrekkelijkheid.
De uitkomst van dit onderzoek laat zien dat de beoordelingen dusdanig weinig van elkaar verschillen, dat de vijf posts als nagenoeg even aantrekkelijk worden beschouwd. Dus als Marketingfacts ze tegelijk op de vastgestelde datum post, neemt het team aan dat de vijf posts op den duur evenveel lezers zullen aantrekken. “De blogposts zijn immers even aantrekkelijk”, is hun redenatie. Of ziet Marketingfacts hier iets over het hoofd?
Gaat heen en vermenigvuldigt u!
Bezoekers van Marketingfacts is ongetwijfeld opgevallen dat bij iedere blogpost te zien is hoeveel mensen hebben ‘doorgeklikt’. Iedere nieuwe bezoeker is mogelijk dus op de hoogte van hoe vaak eerdere bezoekers een artikel hebben aangeklikt (en hopelijk vervolgens ook gelezen). Deze informatie over het aantal lezers maakt het mogelijk dat een beslisproces genaamd preferential attachment gaat optreden (Ormerod 2012).

Voorbeeld van een Marketingfacts-artikel met 33.412 doorkliks.
Preferential attachment kan het makkelijkst worden uitgelegd aan de hand van een voorbeeld, waarbij we even voor het gemak uitgaan van twee posts. Op een bepaald moment hebben 250 lezers de eerste aangeklikt en 50 de tweede. Dit verschil in populariteit tussen de twee is van wezenlijk belang bij preferential attachment. Door de voorsprong in populariteit is de kans namelijk groter dat een volgende bezoeker de eerste en niet de tweede blogpost zal aanklikken. Nieuwe lezers denken mogelijk “als de eerste post zoveel meer bezoekers aantrekt dan de tweede, dan zal wel iets interessants met die eerste aan de hand zijn”.
Met hun voorkeur voor de eerste blogpost imiteren nieuwe bezoekers in feite het keuzepatroon van hun eigen voorgangers. Het resultaat is een sneeuwbaleffect: de eerste post wordt alsmaar populairder, wat maakt dat deze eerder aangeklikt wordt dan de tweede. Het sociale gedrag (imitatie) dat preferential attachment in zich herbergt heeft daarom als gevolg dat de rijken steeds rijker worden.
Maar wat is het effect van preferential attachment als je start met vijf even aantrekkelijke blogposts? Is het juist om te voorspellen dat deze vijf gelijkwaardige stukken na verloop van tijd even populair zullen zijn op een site als Marketingfacts? Zullen ze uiteindelijk ongeveer dezelfde lezersaantallen behalen?
Laat de computer spreken
Nieuwsgierig naar de uitwerking van preferential attachment bij even aantrekkelijke blogposts ben ik aan de slag gegaan met een eigen computersimulatie. Tijdens deze simulatie kozen 2.000 lezers tussen vijf posts. Bij aanvang van de simulatie had iedere post dezelfde gelijke kans (1/5 oftewel 20%) om gekozen te worden, en in die zin waren ze dus gelijkwaardig. Vervolgens koos de ene na de andere lezer welke post ze wilden aanklikken (als in een lange rij bij een stemhokje tijdens een verkiezingsdag). Iedere lezer koos slechts één blogpost. Alvorens te kiezen zag een lezer echter hoe vaak elk artikel tot dan toe aangeklikt was. Lezers wisten dus hoe populair ieder van de vijf posts was bij hun voorgangers, zodat preferential attachment kon optreden. Maar heeft preferential attachment (hoe populairder, des te groter de kans om te worden gekozen) überhaupt enige uitwerking als de stukken bij aanvang gelijkwaardig zijn?
De uitkomst van deze computersimulatie zal voor de meesten opmerkelijk zijn. De gelijkwaardige posts haalden uiteindelijk namelijk niet dezelfde lezersaantallen binnen, verre van dat zelfs. In de figuur linksonder is te zien dat blogpost A uiteindelijk beduidend meer lezers aantrok (908) dan bijvoorbeeld blogpost B (166). Waarom? In een cruciale beginfase maakt een combinatie van toeval en preferential attachment het mogelijk dat artikel A meer aan populariteit wint dan B. In deze beginfase zorgt een deel van de lezers dat A geheel per toeval een kleine voorsprong opbouwt. Preferential attachment bouwt deze kleine voorsprong vervolgens snel uit, en zorgt tevens dat blogpost A deze voorsprong niet meer uit handen geeft.
Herhaal je deze computersimulatie nogmaals (je begint wederom met 5 gelijkwaardige blogposts en laat weer dezelfde 2000 lezers één voor één kiezen), dan krijg je een uitkomst zoals die te zien is in de figuur rechtsonder. Eén opvallend verschil met de eerste simulatie: een andere winnaar komt nu uit de bus, namelijk post C.
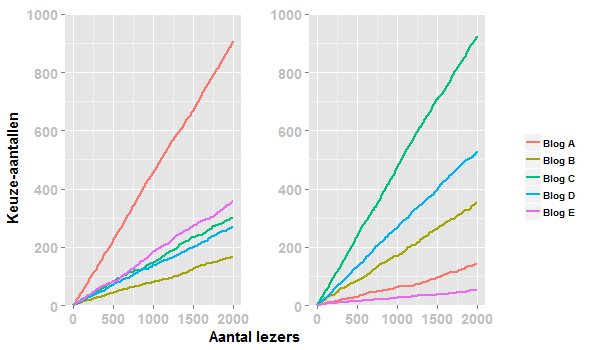
Deze computersimulatie kun je blijven herhalen en iedere keer zul je zien dat de vijf posts op het einde niet dezelfde aantallen lezers halen. Het linkse figuur hieronder vat de resultaten samen van 100 afzonderlijke simulaties.
Ter vergelijking heb ik ook 100 simulaties uitgevoerd zonder preferential attachment (rechtsonder). In ieder van deze 100 simulaties zónder preferential attachment kozen 2.000 lezers weer tussen dezelfde vijf gelijkwaardige posts. De lezers kozen ditmaal echter afzonderlijk van elkaar en zagen dus niet hoe vaak elke post tot dan toe was aangeklikt. De lezers wisten bij het maken van hun keuze dus niet hoe populair ieder verhaal was bij hun voorgangers.
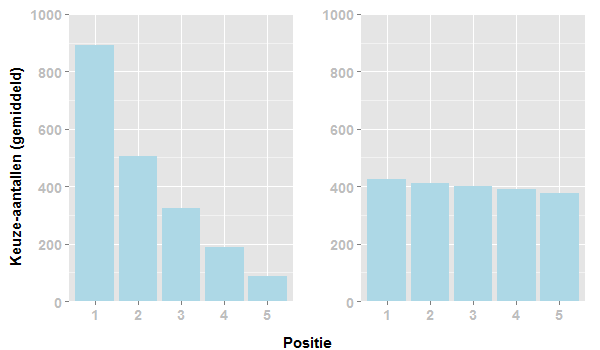
Het verschil tussen de simulaties mét (links) en zónder (rechts) preferential attachment is duidelijk waarneembaar. In de linkse figuur is te zien dat blogposts die op plaats 1 eindigden aanzienlijk meer lezers binnenhaalden dan die bijvoorbeeld eindigden op plaatsen 3 tot en met 5. Gemiddeld over de 100 simulaties haalden de posts op plaats 1 rond de 900 lezers binnen (bijna de helft van alle 2000 lezers!), terwijl die op plaats 3 slechts op zo’n 300 lezers uitkwamen. Bij de simulaties zónder preferential attachment (rechts) daarentegen zijn de verschillen tussen plaatsen 1 tot en met 5 opvallend kleiner.
Belangrijk ook is dat bij de simulaties mét preferential attachment de mate van succes van iedere post vooraf onvoorspelbaar was. Welke uiteindelijk de topposities gingen innemen was volledig gebaseerd op toeval. Onder zulke omstandigheden is het recept voor succes iets wat we dus niet onder eigen controle hebben, namelijk geluk!
Terug naar de werkelijkheid
De bovenstaande computersimulaties roepen mogelijk een vraag op als “Komt preferential attachment überhaupt voor in de echte wereld?” Verschillende onderzoeken wekken de indruk dat preferential attachment inderdaad plaatsvindt. Zo verklaart preferential attachment ondermeer de linkstructuur van internetsites op het World Wide Web (Barabási, 2003).
Maar bij de bovenstaande simulaties is het ook van belang je af te vragen “Worden mensen in de echte wereld eigenlijk wel geconfronteerd met gelijkwaardige keuze-alternatieven?” Ormerod en zijn collega’s (2012) stellen dat consumenten te maken hebben met gelijkwaardige keuze-alternatieven indien (1) geen van de alternatieven boven de anderen uitsteekt wat betreft eigenschappen, en (2) als consumenten het als zeer moeilijk ervaren om verschillen in kwaliteit te onderscheiden tussen de keuze-alternatieven.
Gelijkwaardige keuze-alternatieven lijken soms op elkaar omdat ze voor een deel over exact dezelfde eigenschappen beschikken. Niettemin doen concurrenten daarnaast vaak hun best om producten op bepaalde eigenschappen van elkaar te laten verschillen. Maar deze verschillen zijn vaak zo summier, subtiel of moeilijk inschatbaar dat ze voor de klant van geen enkele betekenis zijn en daardoor min of meer verwaarloosd worden. Op zo’n manier kunnen gelijkwaardige keuze-alternatieven ontstaan.
Nadelige gevolgen?
Maar waar maken we ons nu eigenlijk druk over? Vaak worden consumenten overspoeld met een overvloed aan keuze-opties (vele malen groter dan de vijf posts in de simulaties hierboven). Dikwijls vertonen deze alternatieven onderling ook nog grote gelijkenissen en zijn ze moeilijk van elkaar te onderscheiden. Moeten kiezen tussen zo’n grote hoeveelheid aan alternatieven is vaak moeilijk en kan een demotiverende uitwerking hebben (Iyengar & Lepper, 2000). Daarbij komt nog een ander probleem om de hoek kijken als alternatieven veel op elkaar lijken. Veel beslissers hebben dan namelijk moeite met het vinden van overtuigende redenen waarmee ze hun uiteindelijke keuze kunnen onderbouwen (Scholten & Sherman, 2006). En juist op een overtuigende wijze de uiteindelijke keuze kunnen verantwoorden lijkt belangrijk te zijn voor beslissers (Shafir, Simonson, & Tversky, 1993).
Door preferential attachment wordt een rangorde aangebracht in de alternatieven van een keuzeset. Deze rangorde is gebaseerd op populariteit en komt tot stand door imitatie. Bij het kiezen lijken beslissers voornamelijk hun aandacht te vestigen op de meest populaire items in de rangorde (Ormerod, 2012). Dit inkrimpen van de keuzeset tot de meest populaire alternatieven maakt dat de keuzeset kleiner wordt, en daardoor wordt kiezen waarschijnlijker als makkelijker ervaren. Daarbovenop komt dat de meest populaire alternatieven vaak ‘superieure’ eigenschappen worden toegedicht (Watts, 2011). Deze alternatieven zijn toch niet voor niets zo populair? Voordeel van deze ‘superieure’ eigenschappen is dat ze bij het verantwoorden van de uiteindelijke keuze als zeer overtuigend in de oren klinken. Als je rekening houdt met deze twee voordelen (inperken van keuzeset en bieden van overtuigende redenen) dan lijkt het imitatiegedrag van preferential attachment geen slecht idee.
Maar tegelijkertijd heeft het imitatiegedrag van preferential attachment zijn tekortkomingen. Preferential attachment leert ons ook dat succes gebaseerd kan zijn op toeval. Dit inzicht biedt een andere kijk op de eenzijdige focus op succes (de meest populaire items). Vaak zien beslissers door deze eenzijdige focus niet in dat zowel de meest áls tal van minder populaire items over exact dezelfde ‘superieure’ eigenschappen beschikken (Watts, 2011). Toeval besliste wellicht welke alternatieven de top bereikten en niet zogenaamde ‘superieure’ eigenschappen. Zodoende is het mogelijk dat onterecht ‘superieure’ eigenschappen aan alleen de meest populaire producten worden toegedicht.
Een tweede tekortkoming van de eenzijdige focus op succes is dat tegelijk interessante eigenschappen in minder populaire alternatieven over het hoofd worden gezien. Bepaalde onderlinge verschillen tussen keuze-alternatieven zijn soms moeilijk inschatbaar. Maar verdere verdieping in sommige van de minder populaire alternatieven kan leren dat deze waardevolle kwaliteiten bezitten. Daarom loont het zich de moeite om vaker een blik te werpen op een kleine willekeurige selectie van de minder populaire alternatieven.
Denk dus goed na bij jouw volgende keuze voor een blogpost op Marketingfacts…
Gebruikte literatuur
-
Barabási, A.L. (2003). Linked. New York: Plume.
-
Iyengar, S.S., & Lepper, M.R. (2000). When choice is demotivating: Can one desire too much of a good thing? Journal of personality and social psychology, 79, 995-1006.
-
Ormerod. P. (2012). Positive linking. London: Faber and Faber.
-
Ormerod, P., Tarbush, B., & Bentley, R.A. (2012). Social network markets: The influence of network structure when consumers face decisions over many similar choices. Paper presented at COMPLEX Conference, Santa Fe, December 2012.
-
Scholten, M., & Sherman, S.J. (2006). Trade offs and theory: The double mediation model. Journal of experimental psychology: General, 135, 237-261.
-
Shafir, E., Simonson, I., & Tversky, A. (1993). Reason-based choice. Cognition, 49, 11-36.
-
Watts, D.J. (2011). Everything is obvious. London: Atlantic Books.
Credits afbeelding: Photo © 2011 J. Ronald Lee, CC Attribution 3.0.
Stefan Gelissen is data-analist en analyse-ontwikkelaar bij Datall. Hij heeft uitgebreide kennis over menselijke beslisprocessen en consumentengedrag. Daarnaast heeft hij onderzoekservaring opgedaan aan de Technische Universiteit Eindhoven en in de Verenigde Staten (Michigan State University).
Interessant artikel met waardevolle informatie! Het is misschien ook interessant om te kijken wat er gebeurt door het toevoegen van een Ugly Brother – het bewust toevoegen van onaantrekkelijk product zodat het andere product mooier/beter lijkt – en dit te testen. Wat gebeurt er bijvoorbeeld als je een populair- en een minder populair artikel pakt en de cijfers beïnvloedt. Als je de getallen omdraait, kiezen de mensen dan voor het minder populaire artikel (terwijl zij denken dat het artikel het populairst is) ? En ervaren ze de kwaliteit dan als beter of relevanter?
Ik denk dat er leuke dingen getest kunnen worden bij het beïnvloeden van cijfers die ook nuttig kunnen zijn voor websites. Mensen zijn immers kudde dieren.
Als ik het goed begrijp gaat het hier dus uiteindelijk om het imiteren van de ander, mensen kiezen voor de populariteit van een artikel en niet voor de inhoud. Een verschijnsel dat bij Social Media vaak te zien is en ook nadelige gevolgen kan hebben, ook als artikelen niet gelijkwaardig zijn, namelijk het klakkeloos nadoen van de ander zonder bewust te kiezen.
Ook wel een beetje een eng verschijnsel volgens mij.
Hallo Marieke,
Ik heb dezelfde computersimulaties als in mijn blog uitgevoerd, maar waarbij de items bij aanvang niet gelijkwaardig waren (bij die simulaties verschilden de blogpost in kwaliteit). De resultaten van die simulaties lieten zien dan de ‘beste’ blogposts niet altijd uiteindelijk de meeste lezers binnenhaalden. Het imitatiegedrag maakt dat blogpost van bijvoorbeeld middelmatige kwaliteit uiteindelijk meer lezers behaalden. Bij preferential attachment kan populariteit bij kiezen dus inderdaad zwaarder doorwegen dan inhoud en kwaliteit.
Is het klakkeloos imiteren van de keuze van anderen (zonder zelf bewust te kiezen) een ‘eng’ verschijnsel? Als mensen hun eigen voorkeuren niet meer volgen bij het kiezen, en alleen maar anderen klakkeloos imiteren, dan is dat mogelijk ‘eng’. Aan de andere kant heeft dit imitatiegedrag ook voordelen. Zo haal ik in mijn Marketingfacts-blog bijvoorbeeld aan dat dit imitatiegedrag de keuzeset inkrimpt tot de meest populaire items, waardoor kiezen mogelijk als makkelijker wordt ervaren. Maar je hebt als beslisser natuurlijk altijd de vrije keuze om anderen niet te imiteren en te kiezen voor minder populaire items. Je loopt dan wel de kans dat je buiten de boot valt en bestempeld wordt als een buitenbeentje. Maar geniet je minder van een boek (of liedje) als je weet dat bijna niemand anders dat leest (of naar luistert)?
tramadol online order tramadol medication – tramadol withdrawal regimen
Gerelateerde artikelen
Marketingfacts. Elke dag vers. Mis niks!
Marketingfacts. Elke dag vers. Mis niks!