Conversie-attributie: zoveel meer dan alleen kanalen meten

Bij conversie-attributie wordt met name gedacht aan het toekennen van waarde aan verschillende marketingkanalen, op basis van de bijdrage die ze hebben geleverd aan een conversie. Het geeft inzicht in welke kanalen ervoor zorgen dat bezoekers van je website uiteindelijk converteren en waar het inzetten van je marketingbudget dus het meeste effect zal hebben. Klinkt interessant toch? Maar waarom zouden we conversie-attributie alleen toepassen op kanalen als er nog zoveel meer mogelijkheden zijn?
Momenteel is last-touch-attributie (LTA, of last-click) nog steeds het meest voorkomende model om de waarde van de verschillende kanalen te bepalen. Met het gebruik van alternatieve modellen creëren we meer mogelijkheden, waardoor het concept van conversie-attributie ook toepasbaar is wanneer de uiteindelijke conversie offline plaatsvindt, of wanneer je geïnteresseerd bent in het toekennen van waarde aan acties op je website in plaats van kanalen. Bij gebrek of tekort aan harde conversies, kun je zo ook op soft conversies of ‘engagement’ sturen. Bijvoorbeeld in een situatie waarin relatief weinig – maar waardevolle – offerteaanvragen worden gegenereerd, is het vaak wel mogelijk om te sturen op de voorliggende acties op de website. Maar hoe bepaal je de waarde van álle acties die daar uiteindelijk toe leiden?
Daarvoor is het allereerst belangrijk om te zorgen dat de data goed binnenkomt. Vervolgens zijn er talloze modellen waaruit je kan kiezen om conversie-attributie te berekenen: ik bespreek er hier twee. Uiteindelijk kun je met de modeluitkomst analyseren welke waarde je kunt toekennen aan je variabelen. Wanneer je hebt geanalyseerd welke acties of kanalen het best presteren op basis van de conversie die je hebt gedefinieerd, kun je je campagnes hierop aansturen.
Data voorbereiden
Om de analyse te kunnen uitvoeren hebben we ruwe data uit Google Analytics nodig, dit halen we uit BigQuery (NB: Google Analytics 360 of een ander analytics-platform dat ruwe data verzamelt, is vereist voor een dergelijke analyse). Hierdoor kunnen we de analyse baseren op user level-data waarin we geïnteresseerd zijn. Normaliter zullen bij conversie-attributie de volgende variabelen worden gebruikt:
- fullVisitorId: hiermee herkennen we een unieke gebruiker en kunnen we zien wanneer deze gebruiker terugkeert op de website
- visitStartTime: spreekt voor zich, dit geeft een tijdstempel waardoor de verschillende touch-points in de juiste volgorde kunnen worden gezet
- trafficSource.medium: via welk kanaal komen de bezoekers binnen?
- totals.transactions: geeft aan of er een transactie heeft plaatsgevonden
Sturen op soft conversies
De totals.transactions-variabele meet alleen harde conversies. Als de focus hier niet ligt of als de conversies veelal offline plaatsvinden, zegt deze data dus niet veel. Maar voor alles bestaat een oplossing. Stel dat we niet op de harde conversies kunnen sturen en daarom op een soft conversie willen sturen, dan kunnen we die data inladen. Het is goed om te weten dat ‘Doelen’ vanuit Google Analytics niet in BigQuery terechtkomen. Deze zul je dus zelf uit de data moeten halen. In het geval van een offerteaanvraag, kun je dit uit de eventCategory– en eventAction-variabelen halen (indien dat goed ingesteld staat in bijvoorbeeld Google Tag Manager). Vervolgens creëren we een nieuwe binaire variabele die aangeeft of er wel of geen offerteaanvraag heeft plaatsgevonden. Zo zijn er nog veel meer mogelijkheden om op andere soft conversies te sturen.
Sturen op meer dan alleen kanalen
Tot dusver hebben we ons gericht op een ander soort conversie dan een harde transactie. Maar we kunnen ook de conversiewaarde over acties op een website verdelen, in plaats van over marketingkanalen. Daarbij kun je denken aan:
- Welk device-type draagt meer bij aan een (soft) conversie?
- Hoe vaak klikt iemand op een bepaalde button voordat er een (soft) conversie plaatsvindt?
- Hoe vaak bekijkt iemand een bepaald type pagina voordat er een (soft) conversie plaatsvindt?
Al deze datapunten zijn te vinden in de variabelen device.deviceCategory, eventCategory of eventAction.

Conversie-attributie model 1: Shapley value
Op conversie-attributie is een groot scala aan modellen toepasbaar. Ik bespreek er twee; de Shapley value en het (hogere-orde) Markov-model. De Shapley value wordt door Google zelf gebruikt in zijn data-driven attribution-methode.
De Shapley value is een methode uit de speltheorie, die de waarde tussen spelers in een coöperatief spel verdeelt. Het komt erop neer dat de Shapley value per mogelijke coalitievorming S (deelverzameling van alle spelers N) bekijkt hoeveel speler i bijdraagt aan die coalitie, afhankelijk van de volgorde waarin de spelers zich bij de coalitie voegen.
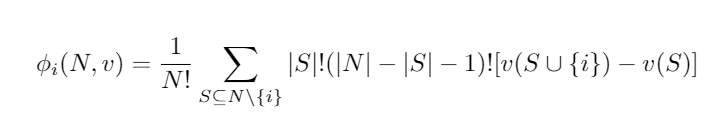
Dit betekent het volgende: stel klant Y heeft een klik-pad van Display gevolgd door Paid Search, wat is dan de marginale contributie van Organic Search als hij aansluit bij dit klik-pad? Waarschijnlijk klinkt dit nog steeds Chinees, dus laten we er een voorbeeld bij pakken dat het idee van de Shapley value zal verduidelijken.
Voorbeeld Shapley value
Veronderstel dat er twee spelers zijn, A en B. Deze A en B kunnen alles representeren, afhankelijk van het doel van de analyse. Bijvoorbeeld:
- A staat voor SEA, B voor SEO (kanalen)
- A staat voor registratie op de website, B voor bekijken van een productpagina (acties)
- A staat voor mobiel, B staat voor desktop (devices)
- Etcetera
Elke speler kan in z’n eentje een bepaalde waarde creëren, maar door samen te werken kunnen de spelers wellicht meer waarde genereren. In dit geval is de waarde de gegenereerde conversieratio. De vraag is echter hoe we dan de gezamenlijk behaalde waarde tussen de spelers verdelen. Laten we de volgende data als uitgangspunt gebruiken voor de voorbeelden:
| Combinatie van spelers | Aantal sequences | Aantal conversies | Aantal non-conversies | Conversie ratio |
| A | 100 | 10 | 90 | 0,1 |
| B | 125 | 15 | 110 | 0,12 |
| A&B | 450 | 80 | 370 | 0,178 |
We gaan per mogelijke combinatie de marginale contributie van elke speler berekenen. We kijken eerst naar alle mogelijke combinaties waarop de coalities gevormd kunnen worden. In het geval van twee spelers is dit relatief simpel: eerst actie A, daarna actie B, of andersom. Als eerst A komt, hebben we een conversie ratio van 0,1. Als B zich dan bij de coalitie voegt wordt de nieuwe coalitiewaarde 0,178, dus draagt B 0,078 bij aan de coalitie. Als eerst B komt, heeft de coalitie een waarde van 0,12, voegt A zich hierbij dan draagt A 0,058 bij aan de coalitie. Dit geeft het volgende overzicht:
| Volgorde | Bijdrage A | Bijdrage B |
| Eerst A, dan B | 0,1 | 0,078 |
| Eerst B, dan A | 0,058 | 0,12 |
| Marginale contributie | (0,1+0,058)/2 = 0,079 | (0,078+0,12)/2 = 0,099 |
Dus als A en B samen een coalitie vormen, krijgt A 44 procent conversiewaarde en B 56 procent.
Met twee spelers is het nog een eenvoudig voorbeeld, maar de complexiteit neemt al snel toe wanneer er meer spelers bij komen. Er zijn 2m mogelijke combinaties waarop coalities kunnen worden gevormd, waarbij m staat voor het aantal spelers. Reken maar uit hoe snel het aantal combinaties onoverzichtelijk wordt. Daarnaast heeft de Shapley value nog een ander nadeel: het kijkt alleen óf een speler of actie voorkomt in de coalitie en niet hoe vaak. Dit is vrij logisch, aangezien de Shapley value gebaseerd is op het idee van Speltheorie en spelers, waarbij een speler niet twee keer mee kan doen in een coalitie. In het geval van conversie-attributie kan een kanaal of actie natuurlijk wel meerdere keren in de customer journey of in het bezoekerspad op de website voorkomen.
Conversie-attributie model 2: Markov model
Het (hogere-orde) Markov-model is gebaseerd op het schatten van overgangskansen, waarbij een opeenvolging van mogelijke events bekeken wordt. Met andere woorden, een eerste-orde Markov-model schat de kans dat je, gegeven je huidige state, overgaat naar de volgende state. In formule-vorm ziet dat er alsvolgt uit:
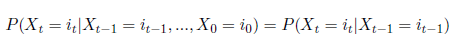
Dit heet het ‘eerste-orde Markov-model’, omdat het is gebaseerd op één geheugenpunt. Echter, het beslissingsproces van een klant voorafgaand aan een conversie, is meestal gebaseerd op meer dan één touch-point. Hier komt het hogere-orde Markov-model in beeld.
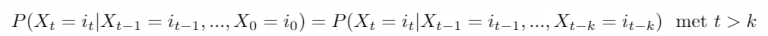
Hierbij houdt het model rekening met het feit dat jij je als bezoeker niet alleen het laatst gebruikte kanaal herinnert, maar de laatste k gebruikte kanalen. Dat resulteert in een betere representatie van de werkelijkheid.
Met behulp van de transitiekansen wordt er een zogeheten Markov-graaf gecreëerd, die bestaat uit de verschillende states waarin jij je als bezoeker kunt bevinden. Oftewel, de states representeren de kanalen die gebruikt worden door de bezoekers. Hier voegen we drie basis states aan toe, namelijk START, CONVERSION en NULL. Deze states hebben de volgende eigenschappen:
- Elk klik-pad begint in START
- Wanneer het pad eindigt in een conversie dan wordt het verbonden door de CONVERSION state naar de NULL state.
- Zo niet, dan slaat het de CONVERSION state over en eindigt het in de NULL state.
- Er zijn geen inkomende paden bij de START state
- Een cyclus is mogelijk wanneer bijvoorbeeld opeenvolgende touch-points hetzelfde zijn.
Zodra alle transitiekansen berekend zijn, berekenen we de totale conversiekans van de graaf. Vervolgens wordt het Removal Effect per state berekend. Het Removal Effect is een methode van Anderl et al. (2016) die het effect op de totale conversiekans berekent zodra we een state weg zouden halen uit de graaf.
Voorbeeld eerste-orde Markov
Om te helpen om bovenstaand te kunnen volgen, gebruiken we dezelfde data als bij de Shapley value om een voorbeeld uit te werken. Aangezien het Markov-model rekening houdt met de volgorde waarin de touch-points voorkomen, moeten de sequences met meerdere touch-points worden opgesplitst . We nemen aan dat dit resulteert in de volgende customer journeys:
| Journeys | Aantal |
| START – A – CONV – NULL | 10 |
| START – A – NULL | 90 |
| START – B – CONV – NULL | 15 |
| START – B – NULL | 110 |
| START – A – B – CONV – NULL | 50 |
| START – A – B – NULL | 250 |
| START – B – A – NULL | 30 |
| START – B – A – CONV – NULL | 120 |
De kans om van START naar A te gaan is 0,59, aangezien 400 van de 675 customer journeys na START naar A gaan (in het geval van een eerste-orde Markov-model). Als we dit voor alle mogelijke transities berekenen, krijgen we de volgende graaf:
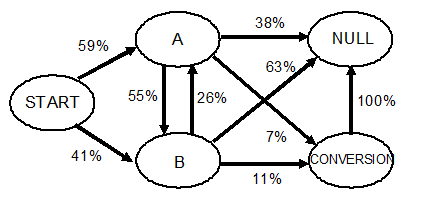
Vervolgens berekenen we alle mogelijke manieren waarop we in de CONVERSION-state kunnen komen. In dit voorbeeld kan dat op vier manieren, namelijk:
START – A – B – CONVERSION – NULL = 0,59 * 0,55 * 0,11 = 0,037
START – B – CONVERSION – NULL = 0,41 * 0,11 = 0,046
START – A – CONVERSION – NULL = 0,59 * 0,07 = 0,043
START – B – A – CONVERSION – NULL = 0,41 * 0,26 * 0,07 = 0,008
Totale conversiekans graaf = 0,133
We hebben een totale conversiekans van 13,3 procent, maar wat nu als A niet zou bestaan? Dan vervallen drie van de vier mogelijke paden waarop we de CONVERSION-state zouden kunnen bereiken. Oftewel, het Removal Effect van A is dan 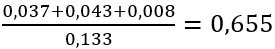 . Doen we dit voor alle kanalen dan krijgen we de volgende Removal Effects:
. Doen we dit voor alle kanalen dan krijgen we de volgende Removal Effects:
| Kanaal/actie | Removal Effect | Removal Effect % | LTA | Shapley |
| A | 0,655 | 49 % | 38 % | 44 % |
| B | 0,677 | 51 % | 62 % | 56 % |
Shapley versus Markov
De derde kolom representeert het Removal Effect, uitgedrukt in een percentage zodat de contributie makkelijk te vergelijken is met andere metrieken. In bovenstaande tabel is het verschil in conversie-attributie te zien tussen de drie modellen. Volgens LTA en Shapley zou B meer hebben bijgedragen aan conversie dan A, terwijl Markov een genuanceerder beeld schetst. Dit komt met name door het feit dat Markov onderscheid maakt in journeys waarin de kanalen/acties in een andere volgorde voorkomen: hierdoor krijgt A een belangrijkere rol.
Alle modellen hebben zo hun voor- en nadelen, er is geen perfect model. Het voordeel van het Markov-model ten opzichte van de Shapley value is dat het rekening houdt met de volgorde waarin de touch-points in de journey voorkomen en het de mogelijkheid biedt tot het includeren van geheugen. Daarnaast wordt het schatten van de Shapley value vanaf zo’n tien variabelen te zwaar om te berekenen. Echter, het Markov-model is afhankelijker van de data-input dan de Shapley value.
Conclusie
Beide methodes hebben als grote voordeel dat ze de hele customer journey meenemen in hun berekening. Dit is extra belangrijk voor een kanaal zoals Display Advertising dat over het algemeen veel aan het begin van een customer journey voorkomt en bij een model zoals last-click nauwelijks conversiewaarde toegewezen krijgt.
Daarnaast bieden deze modellen de mogelijkheid om de spelers of states in te vullen met variabelen die op dat moment van belang zijn. Stel je bent benieuwd welke acties op je website uiteindelijk invloed hebben op een offerteaanvraag, dan kun je die acties als states nemen in plaats van kanalen. Ook kun je zelf bepalen wat als conversie moet worden meegenomen, zolang je maar in je model definieert wat hij moet herkennen als conversie. Dit zorgt ervoor dat je op een andere manier gebruik kunt maken van je data en meer data-driven beslissingen kunt maken met betrekking tot het inzetten van budget en campagnes.
Bron
Anderl, E., Becker, I., von Wangenheim, F., and Schumann, J. H. (2016). ‘Mapping the customer journey: lessons learned from graph-based online attribution modeling.’ International Journal of Research in Marketing, 33:457-474.
Maxime van Leeuwen is 23 jaar, woont in het altijd bruisende Amsterdam, maar komt oorspronkelijk uit ‘t Gooi. Ze heeft Econometrics gestudeerd aan de Universiteit van Amsterdam en mag zich nu Master of Science noemen.
Leuke invalshoek, Maxime.
Vraag: zit er verschil tussen beide modellen qua weging van de tijd vóór de conversie plaatsvindt? Je kunt Display wel meenemen omdat de customer journey hiermee start.
Maar welke impact heeft dit werkelijk gehad op het eindresultaat?
Hi Gerard,
Bedankt voor je reactie! Als ik je goed begrijp stel je twee vragen;
1. In welke mate wordt tijd meegenomen in de modellen?
In principe wordt “tijd” als specifieke variabele niet meegenomen in de modellen. Beide modellen werken aan de hand van touchpoints. Het maakt dus niet uit of er tussen touchpoint 1 en 2 50 minuten zit en tussen touchpoint 2 en 3 vier dagen.
2. Wat is de impact van deze modellen op een kanaal zoals Display m.b.t. toegewezen conversiewaarde?
Allereerst is het goed om te benadrukken dat het probleem endogeen is, d.w.z. dat de resultaten gebaseerd zijn op en beïnvloed worden door een marketingbudget dat al uitgegeven is. Dus als er weinig in een kanaal geïnvesteerd wordt, zal de impact niet drastisch zijn. Maar om je vraag te beantwoorden; in de dataset die wij gebruikt hebben, zien we dat een kanaal als Display wel degelijk meer conversiewaarde toegewezen krijgt t.o.v. LTA. Ondanks dat in die dataset het gebruik van Display redelijk laag was, zagen we dat bij bijvoorbeeld het Markov model Display bijna twee keer zoveel conversiewaarde toegewezen kreeg.
Mocht ik je vraag toch verkeerd begrepen hebben of als er dingen nog onduidelijk zijn, let me know!
Dank voor je uitleg, Maxime.
Ik dacht namelijk dat data-driven attributie model combinatie was van Shapley en tijdsverval model.
Ik begrijp dat Display meer waarde oplevert in bovenstaande modellen dan Laatste klik model. Zeker goed om dit mee te nemen ter meerwaarde van bovenstaande modellen. Ik zou echter wel het volume en kosten hierin meenemen, vandaar mijn opmerking over de impact van Display campagnes!
Gerelateerde artikelen
Marketingfacts. Elke dag vers. Mis niks!
Marketingfacts. Elke dag vers. Mis niks!