Sentimentanalyse: The Making Of …

Enige tijd terug schreef ik al over de nauwkeurigheid en de toekomst van sentimentanalyse. Een korte kennismaking met een ongekend interessant nieuw werkterrein. Op dat stuk kreeg ik heel veel leuke reacties. Geïnteresseerde reacties, vaak met de vraag naar meer verdieping. Daarom nu een vervolg, met meer nauwkeurigheid over de nauwkeurigheid van sentimentanalyse. Hoe werkt het? Welke stappen doorloopt de methode en wat zijn de gevolgen als het binnen een van die stappen misgaat?
Sentiment zonder aannames
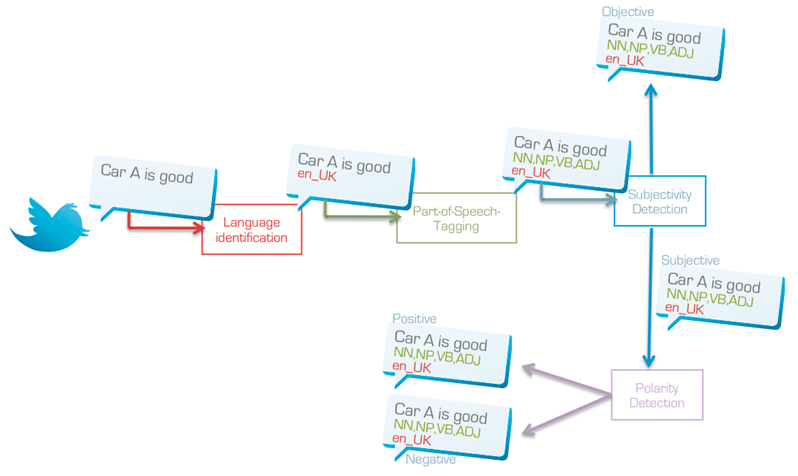
Eerst nog even terug naar de kern. De boodschap van mijn master’s thesis die aan mijn methode van sentimentanalyse ten grondslag ligt, is het analyseren van sentiment zonder aannames te doen. Een methode die zich bijvoorbeeld niet beperkt tot één taal. In mijn vorige stuk gaf ik al aan dat mijn methode uit vier stappen bestaat:
-
Taalherkenning
-
Part-of-speech tagging (‘woordbenoemen’)
-
Subjectiviteitsherkenning
-
Polariteitsherkenning
Taalherkenning via N-grams
Bij het herkennen van de taal maakt de methode gebruik van N-grams. Daarbij delen we een zin op in stukjes van drie letters, zoals voo rbe eld. Op basis van deze karakterreeksen blijk je heel goed te kunnen aangeven in welke taal een tekstje is geschreven. In voorbereiding op mijn scriptie over sentimentanalyse heb ik een onderzoek gedaan naar de beste methode om de taal van korte stukjes tekst te definiëren, en daar kwamen de N-grams als beste uit de bus. Over dat onderzoek schreef ik ook een paper: Graph-Based N-gram Language Identification on Short Texts.
TreeTagger
Voor de part-of-speechtagging maak ik gebruik van de TreeTagger van Helmut Schmid van de University of Stuttgart. Deze tagger herkent zinspatronen en hangt aan elk woord een functie. Een automatische woordbenoemer dus. De uitkomsten daarvan vormen vervolgens de basis voor de volgende stappen.
Mening of geen mening
Bij subjectiviteitsherkenning bepalen we of een zin een mening bevat of niet. Deze stap bestaat in wezen uit een reeks van heel simpele modelletjes. Komt een bepaald zinsverband voor? Of een bepaalde vorm? Op zich zijn het allemaal simpele vraagjes, maar door zo’n vijftig stuks aan elkaar te koppelen, ontstaat er een bijzonder krachtig model.
Wat zegt een zinnetje?
De vierde en laatste stap is de polariteitsherkenning. We weten inmiddels welke taal een zinnetje heeft, welke woorden er zijn en of er een mening in zit. Maar is die mening positief of negatief; dat willen we weten. Dit aspect is het leukste – en moeilijkste – gedeelte van de hele methode. En direct ook hetgeen wat de methode uniek maakt. Bij het ontwikkelen van het model ben ik heel simpel begonnen. Ik heb, in verschillende talen, drie zinnetjes opgeschreven. Een positief, een neutraal en een negatief zinnetje. Vervolgens heb ik die zinnetjes op een heel simpel niveau geanalyseerd. Wat maakt dit zinnetje positief? Die regels verwerkte ik in een model. Vervolgens heb ik nog een aantal veelgebruikte benaderingen getest, maar qua resultaat kon geen enkele aan deze eerste tippen.
Rule Based Emission Model
De polariteitsherkenning is een complexe vorm van zinsanalyse, die allereerst een kernwoord bepaalt. In de zin ‘ik vind jou leuk’ is ‘leuk’ het kernwoord. De woorden eromheen bepalen de betekenis. Hoe dichter een woord bij het kernwoord staat, hoe groter het effect dat het kernwoord heeft op dit woord. Kijken naar woorden alleen is namelijk niet genoeg. Door de betekenis van de woorden eromheen als context mee te nemen, wordt de analyse veel nauwkeuriger. Dat patroon heb ik verder uitgediept tot het, zoals ik het gedoopt heb, Rule Based Emission Model (RBEM). Als alle patronen met de verschillende woorden en hun positie aan de haal zijn gegaan, ontstaat er een ‘uitstoot’; een score. Op basis daarvan wordt een zin positief (score groter dan 0) of negatief (score kleiner dan 0) beoordeeld en is de polariteit een feit.
Voegwoorden
Een aparte categorie woorden zijn de voegwoorden. Het woordje ‘maar’ koppelt bijvoorbeeld verschillende polariteiten aan elkaar. Ook daar houdt het model rekening mee. In de prehistorie van de sentimentanalyse beschreven de heren Hatzivassiloglou and McKeown al de relatie tussen bijvoeglijke naamwoorden en voegwoorden als ‘en’ (samenvoegingen) en ‘maar’ (tegenstellingen). Hun paper Predicting the semantic orientation of adjectives. In Proceedings of the ACL uit 1997 is erg belangrijk geweest voor de verwerking van deze woorden in mijn paper.
Individual step comparison
Een methode ontwikkelen is stap één. Maar het is natuurlijk minstens zo belangrijk om aan te tonen dat deze ook nuttig is. Daarom bestaat pakweg driekwart van mijn scriptie uit experimenten. Daarbij bewandelde ik drie wegen. Allereerst het vergelijken van alle vier de individuele stappen met andere methodes. Individual step comparison dus. Denk daarbij aan het afwegen van mijn polariteitsanalyse tegen de ‘standaard’ methode van woordenlijsten. En ook voor de andere drie stappen (de Part-of-Speech Tagger heb ik zelf niet ontwikkeld en dus ook niet getest) heb ik vergelijkbare methodes gezocht en mijn werkwijze eraan getoetst.
In teamverband
Volgende stap: het proces als geheel. Hoe werken de vier individuele stappen samen en hoe presteren ze als team ten opzichte van andere analysetechnieken die in één stap het complete proces interpreteren? Daaruit bleek een nauwkeurigheid van 69,2 procent. Oftewel: in 69,2% van de gevallen weet de methode het sentiment op social media goed te analyseren.
De zwakste schakel
De derde vraag: wat gebeurt er met de uitkomst als er binnen een van de stappen iets misgaat? Uit mijn onderzoeken blijkt dat de Part-of-Speech Tagging de minste invloed heeft in het geval van een fout. Het wordt echter al moeilijker wanneer de taal verkeerd herkend wordt. Maar ook de polariteitsherkenning drukt een bijzondere stempel op de uitkomst. Als er echter bij de subjectiviteitsherkenning iets misgaat, heeft dat de grootste invloed op het resultaat. Bovendien ligt daar de meeste ruimte voor verbetering, want de subjectiviteitsherkenning scoort het slechtst binnen de hele methode. Maar uiteraard zijn we hard aan het werk om die stap te verbeteren en nauwkeuriger te maken.
Vergelijking met enquêtes
Een kort zijstapje in mijn scriptie is de vergelijking van sentimentanalyse en traditionele enquêtes. Heel zwart-wit gesteld is dat de vergelijking tussen ‘gedwongen’ en ‘ongedwongen’ sentiment. Bij een enquête word je aangespoord om een mening te hebben; het is een soort reactief sentiment. Als je het proactieve sentiment op social media hiermee vergelijkt, zijn er geen duidelijke overeenkomsten te zien. Het gaat te ver om echt te concluderen dat enquêtes dus verschillen van social media, maar ik zou graag eens een diepgaand onderzoek door een professional op het gebied van sociologie hierover zien. De kans is niet groot, maar wellicht dat er verbanden zijn tussen sentiment op social media enerzijds en sentiment in enquêtes anderzijds.
Scriptie in boekvorm
Voor degenen die graag de hele scriptie willen lezen, is er goed nieuws. Mijn master’s thesis komt namelijk ook in boekvorm uit. Ideaal voor op vakantie natuurlijk. Het boek is vanaf eind juli verkrijgbaar bij de betere verkooppunten zoals Amazon (ISBN: 978-3-659-13561-3).
Afbeelding: D. Sharon Pruit (cc)