Optimaliseer je crawlbudget voor betere organische rankings

Wat het is, hoe je die voor jouw website checkt en tips om te optimaliseren
Het crawlbudget: een niet veel gehoorde term in online-marketingland. Crawlen is dat wat Google doet om de inhoud van je website te indexeren. Dit heeft een gigantische invloed op de performance van je organische rankings. Hoe groter je website, en dus hoe meer pagina’s Google moet crawlen, hoe groter de invloed van het crawlbudget wordt.
Veel marketeers weten niet dat je invloed kunt uitoefenen op de manier waarop Google je website crawlt. Anderen weten het wel maar besteden er veel te weinig aandacht aan. Een gemiste kans in mijn ogen. Daarom ga ik je in dit artikel tips geven om je crawlbudget te optimaliseren en vertel ik je waarom je dat wilt.
Wat ís het crawlbudget precies?
Google-bots hebben beperkte middelen om alle pagina’s op je website te crawlen, te indexeren en vervolgens te ranken. Het is niet zo dat alle pagina’s op je website zomaar iedere dag door Google gecrawld worden. Hier zit een limiet op wat we dus het ‘crawlbudget’ noemen. De hoogte van die limiet varieert ook nog eens van dag tot dag.
Bij het toewijzen van het crawlbudget kijkt Google over het algemeen naar drie aspecten:
1. De autoriteit van je website
De belangrijkste van de drie. Google heeft aangegeven dat er een sterke relatie zit tussen autoriteit en crawlbudget. Dat wil zeggen: hoe hoger de autoriteit van je website, hoe meer crawl er toegekend wordt. Website-autoriteit is gebaseerd op het aantal externe (relevante en waardevolle) links naar de website:
2. Servercapaciteit
Google-bots zijn ingesteld om overbelasting van een webserver te voorkomen. Als je website serverfouten retourneert of als de gevraagde URL’s vaak een time-out hebben, is het crawlbudget beperkter.
3. Performance van de website
Zowel techniek als content spelen hierin mee. Hoe meer gedateerde content die niet meer relevant is en niet vernieuwd wordt, hoe minder waarde Google hier aan zal hechten wat resulteert in minder crawlbudget.
Daarnaast spelen ook technische aspecten een rol zoals: laadsnelheid van de website, links naar 404-pagina’s en 301-redirect chains.
Waarom is crawlbudget-optimalisatie belangrijk?
Je wilt dat Google zoveel mogelijk van jouw indexeerbare pagina’s kan vinden en begrijpen. Daarnaast wil je dat ze dit snel doen, zodat ook nieuwe pagina’s die je aanmaakt gauw worden opgepikt. Hoe eerder deze worden ‘gevonden’, hoe sneller jij er je voordeel uit kan halen.
Als je crawlbudget verspilt en deze dus niet geoptimaliseerd is, kan Google je website minder efficiënt crawlen. Er wordt dan tijd besteed aan bepaalde secties op je website die bijvoorbeeld niet belangrijk zijn voor de vindbaarheid. Denk aan pagina’s in het afrekenproces. Dit leidt ertoe dat secties op je website, die juist wel belangrijk zijn voor de vindbaarheid, onontdekt blijven of minder aandacht krijgen. Dat wil je natuurlijk voorkomen.
Hoe meer aandacht er uitgaat naar pagina’s die niet interessant zijn, hoe meer crawlbudget je verspilt. Dit schaadt dan weer de kwaliteit van je website en dus ook jouw SEO-prestaties.
Moet je je zorgen maken over je crawlbudget?
Hiervoor wil ik verwijzen naar wat Google hier zelf over zegt:
“Crawlbudget is niet iets waar de meeste website-eigenaren zich zorgen over hoeven te maken. Als een site minder dan een paar duizend URL’s heeft, wordt deze meestal efficiënt gecrawld.”
De kans is dus heel groot dat crawlbudget voor jouw website geen probleem is als je niet meer dan een paar duizend pagina’s live hebt staan. In dit geval hoeft Google niet teveel moeite te doen om al deze pagina’s efficiënt te crawlen en zullen de SEO-prestaties er ook niet onder lijden.
Werk je wel met een hele grote website (denk bijvoorbeeld aan een webshop met duizenden producten), dan is het zeker aan te raden om met het optimaliseren van het crawlbudget aan de slag te gaan. Niet alleen omdat webshops vaak veel verschillende producten aanbieden en dus veel verschillende pagina’s hebben. Het heeft juist vooral te maken met pagina’s die automatisch gegenereerd worden op basis van URL-parameters. Dit komt voornamelijk wanneer je met filters werkt op een pagina of bij zoekopdrachten die binnen een site gedaan worden.
Een voorbeeld:
Je zoekt op de website van Coolblue naar een wasmachine. Je komt op de overzichtspagina van wasmachines terecht met daarin alle keuzes. De URL van deze pagina is: https://www.coolblue.nl/wasmachines. Vervolgens filter je op merkkeuze (LG) en prijsklasse (max €509), waarna de URL verandert in: https://www.coolblue.nl/wasmachines/merk:lg/prijs:-509. Dit is een URL die wordt aangemaakt op basis van parameters. Je begrijpt dat hier per dag duizenden van worden aangemaakt, wat funest is voor je crawlbudget.
Hetzelfde geldt wanneer je een zoekopdracht doet binnen de website van Coolblue. Stel ik type in de zoekbalk: ‘Wasmachines LG’, dan krijg ik de volgende URL: https://www.coolblue.nl/zoeken?query=wasmachines+lg+. Ook dit is weer een URL die aangemaakt wordt op basis van parameters en dit komt, net als het filteren, ontelbaar vaak voor op zo’n populaire website als die van Coolblue.
Het is in dit soort gevallen erg belangrijk om prioriteiten door te geven aan activiteiten die Google helpen te begrijpen wat er gecrawld moet worden. Toch is het voor ieder formaat website slim om het crawlbudget te optimaliseren. Ook voor kleinere websites wil je namelijk dat Google de meeste aandacht besteedt aan jouw belangrijkste pagina’s en niet aan irrelevante pagina’s voor de vindbaarheid, zoals de interne zoekresultaten. Probeer hier dus kritisch naar te kijken, test het met je eigen website en kijk wat er met je SEO-prestaties gebeurt. Meer informatie over hoe je dit kunt testen voor jouw eigen website vind je later in dit artikel.
Check je eigen crawlbudget
Als website-eigenaar wil je natuurlijk weten wat het crawlbudget van je website is en of deze overeenkomt met het aantal pagina’s binnen je website. Dit kun je vinden in je Search Console-account via de crawlstatistieken. Ga hiervoor in Search Console naar Instellingen en open het rapport over Crawlstatistieken. Je krijgt gedetailleerde informatie te zien over hoe je website gecrawld wordt en of er bepaalde problemen zijn bij het crawlen.
Bovenin het rapport zie je meteen het aantal crawlverzoeken (het crawlbudget) staan, die je vervolgens ook per dag kunt inzien door met je muis op een bepaalde dag te staan. Zie het voorbeeld hieronder:
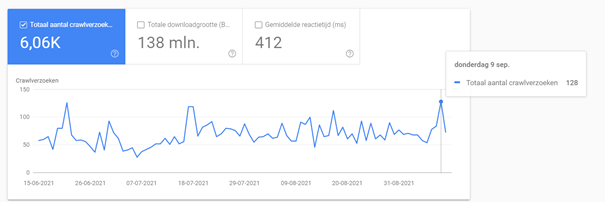
Ook kun je in dit rapport gemakkelijk vinden naar welke pagina’s op dit moment de meeste aandacht uitgaat. Klik daarvoor op het volgende veld:
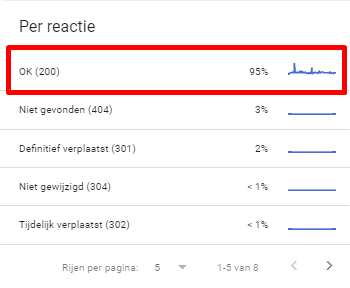
Overigens kun je ook doorklikken op een van de andere velden, maar het percentage aan pagina’s met een 200-code hebben vaak veruit het grootste aandeel.
Klik je hierop door, dan krijg je een hele lijst te zien met URL’s die de afgelopen drie maanden gecrawld zijn. Inclusief datum en tijd. Deze lijst kun je sorteren op URL, waardoor je alle identieke URL’s onder elkaar op volgorde ziet staan. Zo zie je precies hoe vaak een bepaalde URL in de afgelopen 3 maanden gecrawld is.
Scroll regelmatig door deze lijst om te zien of er bepaalde secties zijn binnen je website die veel gecrawld worden, maar die niet interessant zijn voor de vindbaarheid. Heb je die gevonden? Dan kun je met onderstaande tips aan de slag!
Tips om het crawl budget te optimaliseren
Je weet nu wat het crawlbudget is, hoe je die van jouw website checkt en waarom je dit moet optimaliseren. Gebruik de volgende tips om die optimalisatie uit te voeren.
1. Manage het robots.txt bestand
Dit is een no-brainer en de belangrijkste stap om met het optimaliseren van je crawlbudget aan de slag te gaan. Robots.txt is een bestand in de hoofdmap van je site. Zoekmachinebots gebruiken het om te achterhalen welke delen van je site ze wel of niet mogen crawlen. Je kunt dit bestand vinden via domein.nl/robots.txt.
Je robots.txt-bestand kun je handmatig instellen, of met behulp van een plug-in. Mocht je een bepaalde sectie van je website niet willen laten crawlen, dat kun je deze sectie ‘disallowen’. We pakken het eerdere voorbeeld van Cooblue erbij, betreffende de zoekopdrachten binnen de website. Dit resulteerde in de volgende URL: https://www.coolblue.nl/zoeken?query=wasmachines+lg. Als je deze resultaten niet wilt laten crawlen, betekent het dat je de volgende regel op disallow zet: /zoeken?. Alle resultaten die beginnen met deze regel zullen dan niet gecrawld worden.
Wees kritisch op wat je wel en niet wilt laten crawlen
TIP: Check Google Analytics om te zien wat bepaalde pagina’s je opleveren in traffic en/of omzet/leads. Het kan interessant zijn om bepaalde pagina’s uit te sluiten die al jaren niets hebben opgeleverd en die je ook niet van plan bent om te gaan optimaliseren.
Hou Google Analytics dus naast je crawlstatistieken die je in Search Console kunt vinden en wees kritisch op wat je wel en niet wilt laten crawlen. Zie je in de crawlstatistieken dat er veel aandacht uitgaat naar pagina’s waarvan je in Analytics ziet dat deze al heel lang niks opleveren, kies er dan voor om deze niet meer te laten crawlen. Zo deel je je crawl budget dus heel efficiënt in! Je laat de aandacht dan namelijk uitgaan naar pagina’s die ook daadwerkelijk iets opleveren. Dit zal ook ten goede komen aan de gehele kwaliteit van jouw website.
Let wel op dat je niet bepaalde resources zoals CSS en Javascript disallowed. Deze zul je namelijk regelmatig terugvinden in de crawlstatistieken, maar niet in Analytics. Echter zijn deze resources wel van belang voor bots om de volledige content van een pagina te zien.
2. Kijk uit voor redirect-chains
Staan er een groot aantal 301-redirects achter elkaar ingesteld, dan zal Google op een gegeven moment stoppen met het volgen van deze redirects en wordt de bestemmingspagina niet gecrawld.
Daarnaast is iedere redirect een verspilling van het crawlbudget. Zorg er dus voor dat je een redirect niet vaker dan twee keer achter elkaar gebruikt en alleen als het absoluut noodzakelijk is.
Zorg er daarnaast ook voor dat, mocht je toch veel redirects hebben ingesteld, alle interne hyperlinks meteen aangepast worden naar de bestemmingspagina. Dit kun je bijvoorbeeld checken met een tool als Screaming Frog.
Voorbeeld:
Op de homepagina staat een link naar Pagina A. Pagina A wordt geredirect naar Pagina B. Dit betekent dat je de hyperlink die op de homepagina staat naar Pagina A al meteen moet aanpassen naar Pagina B, zodat Google niet nog een extra stap heeft te nemen om de bestemmingspagina te vinden. Dat scheelt dus weer crawlbudget.
Voor WordPress-gebruikers is de plug-in Better Search Replace een goede manier om dit snel en gemakkelijk te doen, op grote schaal.
3. Minimaliseer interne links naar 404-pagina’s
Net als dat je niet wilt dat een bezoeker op jouw website terecht komt op een 404-pagina, wil je ook niet dat de crawlers van Google dat doen. Dat is niet alleen schadelijk voor de kwaliteit van je website. Het kost ook crawlbudget.. Iedere link naar een 404-pagina moet worden gecrawld, wat je uiteraard niet wilt. Zorg er dus voor dat er binnen jouw website zo min mogelijk (het liefst geen één) interne links te vinden zijn die leiden naar een 404-pagina. Ook dit zou je bijvoorbeeld kunnen checken met Screaming Frog.
4. Update je XML-sitemap zo nu en dan
Een XML-sitemap dient als een inhoudsopgave van je website. Hierin staan de pagina’s die je door Google wilt laten crawlen. Het is dus af te raden om hier pagina’s in te hebben staan die voor de vindbaarheid niet interessant zijn. Als ze in de sitemap staan, geef je juist aan dat je ze gecrawld wilt hebben en zal Google dus de moeite nemen om deze pagina’s toch te crawlen. Dat zijn tegenstrijdige signalen die je doorgeeft. Zorg er dus voor dat je regelmatig de XML-sitemap checkt en indien nodig opschoont.
5. Een no-follow attribuut plaatsen op interne links
Interne links zijn voor SEO van groot belang. Ze sturen namelijk linkwaarde door naar andere pagina’s en ze helpen zoekmachines deze pagina’s makkelijker te vinden. Toch is het ook zo dat iedere interne link crawlbudget in beslag neemt. Deze link moet namelijk worden gevolgd. Staan er heel veel interne links naar pagina’s die niet interessant zijn voor de vindbaarheid (voor een webshop kunnen dit bijvoorbeeld interne links naar het winkelmandje zijn), dan kun je besluiten om deze links niet te laten volgen. Dit kan met behulp van een no-follow attribuut. De naam zegt het al, dit attribuut zorgt ervoor dat bots deze link niet volgen, waardoor deze dus ook geen crawlbudget in beslag nemen.
Overige tips:
- Vermijd te grote afbeeldingen
- Verbeter de laadsnelheid van je website
- Gebruik hreflang-tags bij een internationale website
Conclusie
Als je je nog steeds afvraagt of crawlbudget-optimalisatie belangrijk is voor jouw website, dan is het antwoord duidelijk: ja, dit is het zeker. Het crawlbudget is, was en blijft in de toekomst een belangrijke factor om in gedachten te houden.
Hopelijk helpen deze tips je om je crawl budget te optimaliseren en je SEO-prestaties te verbeteren. Laat het vooral weten of dat is gelukt!

Als Online Marketeer word ik ontzettend blij van soepel draaiende websites die goede resultaten behalen. Dit is dus ook exact de reden waarom ik me heb ontwikkeld tot Online Marketing Specialist. Inmiddels heb ik 5+ jaar ervaring binnen online marketing. In die tijd heb ik al hele mooie optimalisaties mogen doen voor meerdere bedrijven. Mijn specialiteit ligt bij SEO. Als SEO specialist zorg ik er kort gezegd voor dat een website goed gevonden wordt in de gratis zoekresultaten van Google en andere zoekmachines. Aan alleen bezoekers heb je echter niet zoveel, ze moeten overgaan tot conversie of aankopen. Daarom denk ik ook mee hoe we de conversie op de website kunnen verhogen. Met een écht goede website zet jouw bedrijf op die manier de volgende stap naar stevige groei. Meer websitebezoekers, meer omzet en meer resultaten! Dat is toch hartstikke tof? Dit is in ieder geval waar ik heel veel energie van krijg. Ik hou ervan om écht samen aan de slag te gaan. We werken dus niet op basis van eenzijdige communicatie, maar echt samen. Ik beschouw mijn klanten als partners en transparantie staat bij mij voorop.
Mooi artikel. Enkele kanttekening wel bij het plaatsen van nofollow links. Je ziet dat dit soms bijna krampachtig gedaan wordt, terwijl het niet nodig is. Google heeft zelf aangegeven dat je standaard interne links wel allemaal kunt laten volgen. Hebben we het over vele duizenden (miljoenen?) pagina’s dan wordt het een ander verhaal. Het verhogen van je crawl budget d.m.v. meer externe links, en het optimaliseren van de prestaties van je website hebben meer invloed.
Hey Axel, altijd nuttig om je crawl budget te optimaliseren. Wat zijn jouw ervaringen met status ‘Gevonden – momenteel niet geïndexeerd’ in Dekking? Ik zie de laatste maanden bij verschillende projecten soms ineens plukken URLs hier opduiken die compleet random lijken te zijn in vergelijking met andere (nieuwe) content. En die soms ook weken of maanden in deze status blijven hangen. De verklaring die Google hier zelf voor geeft (“Doorgaans wilde Google in dit geval de URL crawlen maar was de site overbelast waardoor Google het crawlen opnieuw moest plannen. Dit is de reden waarom de laatste crawldatum leeg is in het rapport.”) vind ik in alle gevallen niet erg logisch, dus ik vermoed dat er iets anders achter zit… Wellicht capaciteitsissues bij de crawlers? Dit ook in relatie tot recente bugs/achterstanden bij GSC en de hele CWV uitrol die (als ik het goed begrijp) voor een deel ook een crawl bezuinigingsoperatie is? Ben benieuwd naar jouw mening/ervaring 🙂
Hi Joost!
Hoop dat je het artikel als nuttig hebt ervaren! Ik moet je heel eerlijk toegeven dat wij dit probleem op het moment nergens terug zien in onze accounts. Dat maakt het voor mij ook wat lastiger om hier antwoord op te geven. Dit zou inderdaad een logisch vervolg kunnen zijn van de issues die GSC niet zo lang geleden nog had. Denk niet zozeer dat het te maken heeft met de CWV uitrol eerlijk gezegd.
Wellicht dat het te maken heeft met de servercapaciteit van de website waardoor er niet genoeg aanvragen gedaan kunnen worden om alle URL’s te crawlen? Dit zou je wellicht nog even kunnen controleren in de crawlstatistieken van het account. Maar als je aangeeft dat het bij meerdere accounts te zien is, denk ik toch eerder aan het eerste, wat je zelf ook al aangeeft; een wat breder probleem wat nog het gevolg is van de GSC issues van enige tijd terug.
Gerelateerde artikelen
Marketingfacts. Elke dag vers. Mis niks!
Marketingfacts. Elke dag vers. Mis niks!