9 misverstanden over duplicate content

Duplicate content, vrijwel iedere website heeft er mee te maken en bijna iedereen kent het begrip. Maar er gaan ook veel misverstanden of broodjeaapverhalen de ronde. Zorgt duplicate content nu wel of niet voor een penalty? Of is het juist handig om duplicate content onder de vouw te plaatsen?
Onlangs hield Google’s John Mueller een Google Webmaster Central office-hours hangout (een soort webinar voor webmasters via Google Hangouts) over dit onderwerp waarin alles nog eens uit de doeken werd gedaan. Een mooie aanleiding voor dit artikel om die misverstanden de wereld uit te helpen.
Dit artikel is geschreven samen met Chantal Smink, Sr. SEO-consultant bij Maxlead
Wat is duplicate content?
Duplicate Content houdt grofweg in dat dezelfde content te bereiken is op verschillende URL’s. Duplicate content kan per ongeluk ontstaan door technische instellingen. Denk bijvoorbeeld aan een site die draait op zowel www als non-www, of http en https of door het gebruik van tagging parameters in de URL (?utm=). Maar bijvoorbeeld ook doordat er mobiele pagina’s zijn die (door het ontbreken van correcte canonical en alternate tags) een duplicaat zijn van de desktopwebsite of printvriendelijke pagina’s zoals PDF’s.
Van duplicate content is echter ook sprake wanneer iemand jouw content ‘leent’ en op z’n eigen website plaatst of wanneer jij standaard content van fabrikanten gebruikt op jouw website. Net als alle andere concurrenten.
Waarom kan duplicate content een probleem zijn?
Duplicate content kan problemen geven omdat zoekmachines in principe niet meerdere keren dezelfde content willen laten zien aan hun gebruikers. Ze zullen dan vaak keuzes gaan maken: welke pagina laat ik wel zien en welke niet. Het kan dan gebeuren dat Google een andere URL prefereert dan jij en dus de ‘verkeerde’ URL laat zien in de zoekresultaten.
Een ander probleem met duplicate content is dat de spiders alle pagina’s in jouw site moeten crawlen om daarna te constateren dat er pagina’s duplicaat aan elkaar zijn. Dit gaat ten koste van je crawlbudget en dat is dus zonde. Het kan namelijk gebeuren dat andere pagina’s niet (of niet zo snel) gecrawld worden omdat je budget op is.
Daarnaast zijn wij van mening dat het beter is om Google waar mogelijk te helpen. Niet alleen belast je hun opslagruimte minder, je laat ook duidelijk zien dat je zorg aan je website hebt besteed. Want hoe ‘leuk’ vindt Google het als hun servers onnodig belast worden met duplicate content die per ongeluk ontstaan is? Nu lijkt dat geen probleem, maar hoe is dat in de toekomst? Door een en ander netjes te organiseren word je er sowieso niet slechter van en wellicht juist wel beter.
Hoe herken je duplicate content?
Duplicate content binnen je eigen website kun je op een aantal manieren herkennen. Zo kan het zijn dat je in Google Search Console de melding krijgt dat er duplicate title tags en meta descriptions zijn geconstateerd. Hier komen we later nog specifiek op terug.
Wanneer je een zoekopdracht doet en je ziet een andere URL van je website in de zoekresultaten dan de URL die je zou verwachten, kan dit ook een indicatie zijn dat je website duplicate content bevat.
Een andere indicator in Google Search Console kan zijn dat je enorme pieken ziet in het aantal gecrawlde pagina’s in je crawlstatistieken. Heb jij een website met 100 pagina’s, maar zie je in de crawlstatistieken dat er per dag veel meer pagina’s gecrawld worden, dan kan dit er ook op wijzen dat je duplicate content hebt. In dit geval komt dat vaak voort uit technische problemen.
Hoe gaat Google met duplicate content om?
We hebben al eerder benoemd dat Google in veel gevallen een keuze zal maken tussen de duplicate pagina’s en er slechts één zal tonen. Maar ook de zoekopdracht beïnvloedt hoe Google ermee omgaat. Stel: je hebt een website voor Nederland en een variant voor België. De gebruiker zoekt op ‘bezorgkosten [websitenaam]’. In dat geval kan het gebeuren dat Google per ongeluk de pagina voor het verkeerde land laat zien. Google ziet namelijk dat de pagina’s duplicaat zijn aan elkaar en zal waarschijnlijk gaan kiezen welke van de twee hij wil laten zien. Het is goed mogelijk dat autoriteit hierbij dan een maatstaf is voor Google.
Als de Nederlandse site veel meer autoriteit heeft dan de Belgische, kan het dus zijn dat Google de Nederlandse bezorgkostenpagina laat zien in België. Pas als men zoekt naar ‘bezorgkosten [sitenaam] België”, dan weet Google dat de gebruiker echt die éne pagina zoekt. Op dat moment is het geen issue meer dat de pagina’s duplicate zijn elkaar, omdat ze voor deze zoekvraag toch onderscheidend genoeg zijn.
We hebben het echter ook al een aantal keer zien gebeuren dat bij algemene zoekopdrachten, Google toch meerdere keren dezelfde content laat zien. Trouwens, onderaan de SERP’s (aan het einde van alle pagina’s) kan Google aangeven dat er meerdere ‘vergelijkbare’ resultaten zijn. De gebruiker kan hier alsnog inzicht in alle pagina’s krijgen door op de link te klikken.

Nu duidelijk is wat duplicate content is en hoe Google er mee omgaat, is het tijd voor de misverstanden. Een aantal hiervan zijn hardnekkig en doen al langere tijd de ronde. Andere zijn wat onbekender. Goed om er eens negen op een rijtje te zetten.
1. Duplicate content kan een penalty veroorzaken
Hier kan een kort antwoord op gegeven worden. Nee, duplicate content kan geen penalty opleveren en is ook geen criterium voor Google Panda. Hoe zit het dan met scraper websites, doorway pages en websites die aan automatische content spinning doen? Deze websites kunnen wel een penalty oplopen maar niet vanwege duplicate content, maar door webspam. Met andere woorden: deze websites gaan in tegen de richtlijnen van Google en worden daarom bestraft.
Heb jij dus veel duplicate content, maar is het geen spam? Dan hoef je niet te vrezen voor een straf vanuit Google.
2. Doordat ik standaard productteksten gebruik (bijv. van de fabrikant) heb ik duplicate content en zal mijn site slecht presteren
Wanneer je standaardteksten van een leverancier gebruikt zal dit zeer waarschijnlijk duplicate zijn aan content op andere sites. Andere afnemers van die leverancier zullen namelijk ook vaak die teksten gebruiken. Vormt dit dan direct een probleem voor jouw resultaten in Google? Nee, dat hóeft niet, wel is het dan goed om dit manco op andere manieren te compenseren.
Zorg ervoor dat je op een andere manier uniek bent en relevanter voor de eindgebruiker dan jouw concurrent. Heb je bijvoorbeeld extra informatie over die producten? Geef je gebruiksinstructies? Vertel je meer over wat het product kunt of voor welke toepassing je dit product goed kunt gebruiken? Heb je ze getest en doe je daarvan verslag in bijvoorbeeld video’s? Heb je unboxingvideo’s? Is je site voorzien van reviews? Door dit soort relevante content toe te voegen, kun je toch zorgen dat je relevanter bent dan je concurrent en kun je daardoor alsnog beter presteren.
3. Een pagina die één op één vertaald is, is duplicate content
Nee, Google ziet een pagina die één op één vertaald is niet als duplicate content. Het gaat hier dan wel om pagina’s die handmatig vertaald zijn, door een menselijke hand en daarmee relevant zijn voor de eindgebruiker. Wanneer jij in je eigen taal een zoekopdracht doet dan verwacht je ook resultaten die in jouw taal geschreven zijn. Als de vertaalde content hierdoor relevant is voor gebruikers dan voorzie je deze gebruikers juist in hun behoefte. Alleen maar goed dus.
Kleine tip; laat het gebruik van de automatische Google Translate-functie voor ieders plezier vooral achterwege. Het is goed mogelijk dat dit helemaal geen kwalitatieve content oplevert en dus nog steeds niet voldoet aan de eisen die Google aan goede pagina’s stelt.
4. Het is beter om duplicate content onder de ‘vouw’ te plaatsen
Het precieze antwoord van Google op deze vraag is: “We don’t look at it so much”. Er wordt dus niet glashard aangegeven dat het effect heeft. Wel is het zo dat Google per pagina kijkt naar unieke stukken content die toegevoegde waarde hebben voor gebruikers. Daarbij maakt het geen verschil of jouw duplicate content boven of onder de ‘vouw’ staat. Als jij toegevoegde waarde hebt die onder de ‘vouw’ staat (op zich zonde, maar dat is een andere discussie) en daardoor relevant bent voor een zoekopdracht dan is de kans toch groot dat jouw website getoond wordt in de zoekresultaten.
5. Mijn concurrent heeft meer duplicate content dan ik, dus ik moet hoger ranken.
Nee, zo werkt het helaas niet. Je kunt niet weten wat er aan de hand is en waarom een concurrent toch beter rankt dan jij. Ranken is ook een behoorlijk subjectief begrip. Welke zoekopdracht is dan het criterium? En aangezien zoekresultaten steeds verder gepersonaliseerd zijn en iedereen wat anders kan zien, kun je eigenlijk niet meer stellen dat je hoger of lager rankt dan je concurrent.
Maar kijken naar de concurrent komt helaas nog maar al te vaak voor. John Mueller zegt hierover letterlijk: “Dit is geen sterk argument, zorg ervoor dat je relevanter bent dan zij, dan ga je het vanzelf beter doen”. Een waarheid als een koe, maar wel een typisch Google antwoord. Welkom in 2015.
6. Door de canonical tag ben ik er zeker van dat Google de juiste URL in de zoekresultatenpagina’s laat zien.
Je kunt een canonical tag gebruiken om bij duplicate content aan te geven welke URL je graag geïndexeerd wilt hebben. Coolblue doet dit bijvoorbeeld wanneer een artikel in meerdere webshops (en bij hen dus meteen op meerdere domeinen) wordt aangeboden.
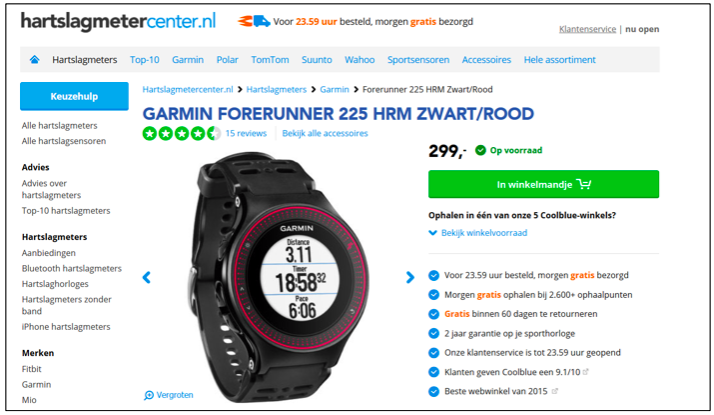
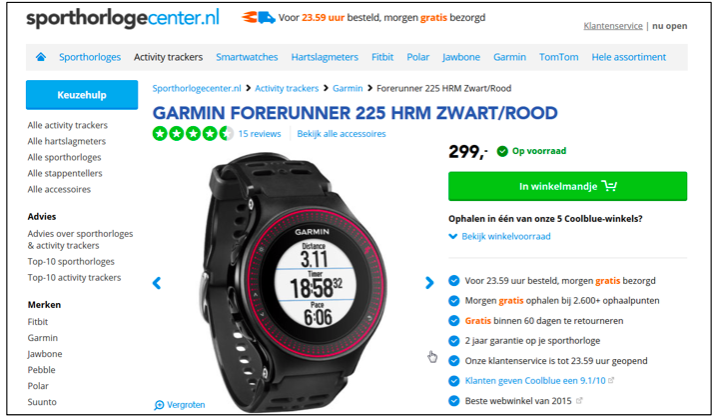
Met een canonical tag vraag je zoekmachines om niet URL A maar URL B te indexeren. Het is goed om te weten dat een canonical tag slechts een verzoek is, zoekmachines mogen dit dus negeren. Dit kan gebeuren wanneer andere signalen (interne of externe links) erop wijzen dat de andere URL de juiste zou zijn.
Wil je absoluut de juiste URL getoond hebben in de zoekresultaten? Dan heb je zwaarder geschut nodig zoals redirects of de meta tag robots noindex. Welke van deze twee methoden je het beste kunt gebruiken, hangt dus af van jouw situatie. Maar in dit soort gevallen kan het middel wel eens erger zijn de kwaal. Besef dus goed wat de gevolgen zijn van je keuze.
7. Pagina’s met duplicate title tags en meta descriptions zijn ook duplicate content
Nee, hoewel het veel beter is om voor iedere pagina unieke title tags en meta descriptions te schrijven ziet Google pagina’s met identieke meta data niet direct als duplicate content. Google zal aan de hand van andere signalen kunnen zien dat een pagina toch niet duplicate is, bijvoorbeeld door de tekstuele inhoud, subkoppen of optimalisatie van media.
In een eerder filmpje geeft voormalig Google-er Matt Cutts trouwens aan dat je beter geen meta data kunt invullen bij duplicates. Spreekt Google zichzelf tegen? Nee, dat hoeft niet. Door voor alle pagina’s een unieke title tag en meta description te maken, geef je een signaal af dat je zorg hebt besteed aan je site en dat is nooit slecht. Bovendien kun je op die manier proberen om een betere description in de zoekresultaten te krijgen.
Máár, zo adviseert John Mueller, wanneer je gebruik maakt van de rel=”prev”/rel=”next”-tag dan is het juist beter om gelijke title tags, meta descriptions en zelfs headings te gebruiken op iedere pagina. Op die manier laat je zien dat er ook daadwerkelijk sprake is van een opvolgende, bij-elkaar-horende-reeks.
Wil jij checken of je duplicate title-tags of meta descriptions hebt in jouw site? Raadpleeg dan Google Search Console (onder Zoekopmaak HTML Verbeteringen).

8. Google laat in geval van duplicate content altijd de originele bron zien
Helaas pindakaas, zo werkt het niet. Het is vaak onmogelijk voor Google om te bepalen wie de originele bron is. Je kunt natuurlijk kijken welke URL als eerste is gedetecteerd, maar dat geeft geen 100 procent zekerheid dat die website ook echt de eerste was. Het kan namelijk best zijn dat website A de content al twee weken op de site had staan, maar later is gecrawld door spiders dan site B. In dat geval zou alsnog site B aangemerkt worden als de originele bron.
Uit de reactie van John kun je opmerken dat dit een van de dingen is waarbij Google er niet in is geslaagd een oplossing te vinden. Heb jij dus hét idee hebben om dit aan te pakken? Bel dan gerust een keer naar Google.
Wil je er zeker van zijn dat Google jouw website laat zien in de zoekresultaten, dan zul je soms als een leeuw je waardevolle content moeten beschermen. Dit betekent scherp zijn op het feit of jouw content wordt gekopieerd, partijen vragen die jouw content overnemen om een link naar jouw website of liever nog: vraag ze om alleen de inleiding over te nemen en daarna naar jouw site te verwijzen. Als dit niet werkt en er is toch sprake van diefstal, dan moet je het hogerop zoeken. Ook op jouw content rust auteursrecht, dus anderen mogen dat simpel weg niet zomaar gebruiken.
9. Twee sites in dezelfde taal voor verschillende landen is ook duplicate content
Nee, volgens John Mueller is dit geen duplicate content. Zijn argumentatie is dat er lokale verschillen tussen de websites zitten. In de praktijk zien wij vaak dat er toch de nodige problemen door kunnen ontstaan, waardoor wij van mening zijn dat het wel degelijk duplicate content is. Het kan namelijk gebeuren dat de verkeerde pagina rankt in het verkeerde land. Onhandig als gebruikers niet in een ander land kunnen converteren, maar alleen op de site van hun eigen land.
Een oorzaak van dit soort problemen is dat de content vaak helemaal niet per land en taal wordt gemaakt, maar dat er een versie is met content en deze klakkeloos op meerdere sites voor meerdere landen wordt geplaatst. Er wordt geen rekening gehouden met taalgebruik of cultuur. Stel je hebt een site voor België en Nederland. Het kan dan dus zijn dat de Nederlandse site (per ongeluk) rankt in België. Zelfs werken met de juiste landextensies (.be en .nl) biedt geen garantie dat het goed gaat. Google wordt best slim en geeft zelf aan dat ze correct met landextensies kunnen omgaan, onze ervaring leert helaas anders.
Om dit soort problemen op te lossen kun je in het geval van een .com domein geo-targeting instellen in Google Search Console. Je vindt deze optie onder Zoekverkeer Internationale targeting. Ook kun je zogenaamde ‘hreflang-tags’ inzetten waarbij je aangeeft welke pagina voor welke taal of welk land gemaakt is. Hoewel officieel niet nodig kun je dit ook doen als je site werkt met landextensies zoals .nl of.be.

Tot slot
De soep wordt allang niet meer zo heet gegeten als dat deze ooit opgediend werd. Wat duplicate content is en hoe erg dat is, is niet voor alle gevallen gelijk. Duplicate content is echter niet altijd handig en kan je in sommige gevallen benadelen als het op prestaties aankomt, maar zal je nooit een penalty opleveren. Google wordt steeds slimmer en beseft dan duplicate content ook niet altijd op te lossen is. Wel wordt je er beter van als je slim omgaat met je crawl budget en een op eigenlijk elk vlak een paar stappen meer zet dan je concurrent.
Google Webmaster Central Office Hours Hangout
Google organiseert zeer regelmatig zogenaamde Google Webmaster Central office-hours hangout (let op, office hours is een relatief begrip. Als wij klaar zijn met werken begint in delen van de US de werkdag pas). Deze office hours zijn online samenkomsten waarbij webmasters vragen kunnen stellen aan Google experts, maar er is ook ruimte voor discussie. Wil jij ook zo’n hangout volgen? Bekijk dan hier de lijst met data. Niet altijd is van tevoren bekend waar een sessie overgaat. Het SEO-team van Maxlead volgt alle Hangouts en zal er verslag van doen als er interesse inzichten naar voren komen.
Marc Thierrij is Sr. SEO consultant bij Maxlead. Hij is in 2010 in aanraking gekomen met SEO om het daarna niet meer los te laten. In het verleden was hij werkzaam bij de Linkbuilding Specialist en als inhouse SEO specialist bij TellUs. Vanuit de rol als Sr. SEO consultant bij Maxlead adviseert hij grote en kleine bedrijven uit verschillende branches bij het verbeteren van de organische vindbaarheid.
Goed artikel Marc. Als toevoeging wil ik nog even inhaken op interne en externe duplicate content. Dit artikel gaat vooral in op externe duplicate content (tussen verschillende domeinen die wel of niet van dezelfde eigenaar zijn). Ik kom ook vaak interne duplicate content tegen (binnen dezelfde website). Vooral webshops met vele vergelijkbare artikelen beschrijven dan eigenschappen en gelijkaardige kenmerken met een zelfde tekstblok. Soms zijn verschillende pagina’s binnen een website voor 90% gelijk waardoor je jezelf ook tekort doet.
Vraagje, ik heb 2 websites. Als ik op beide websites een unieke review ga schrijven over een product maar op beide pagina totaal anders. Dus andere kopjes en andere titel en ga op beide reviews er anders op in.
Dan zijn er toch geen problemen en kan ik op beide nog hoog scoren in google ?. Heb namelijk een pagina waar ik 1000 bezoekers op heb en een net beginnende pagina.