How-to: tips om te starten én verkopen met big data in kleine en grote organisaties

Big Data bepaalt jouw vakantiepret
Ieder jaar kijkt iedereen weer uit naar een paar weken vakantie. Die weken moeten dan ook goed worden besteed. Dat betekent bestemmingen en accommodaties vergelijken. Nog wel. Want in de toekomst gebruikt de reisorganisatie big data om die perfecte vakantie voor te stellen. Tegen de scherpste prijs en op het moment dat het jou het best uitkomt. Om zo de concurrentie af te troeven. De site vertelt er alvast bij welke beoordeling je gaat geven. En dit kan met veel meer producten. In dit artikel tips om big data succesvol in te zetten in kleine en grote organisaties.
Vroegboekkorting of last minute?
In januari buitelen reisorganisaties over elkaar om de vakantieganger te verleiden tot een vroege boeking. Ondanks alle ‘vroegboekkortingen’ is januari niet altijd de beste maand om zo goedkoop mogelijk een reis te boeken. Skyscanner analyseerde voor alle populaire vakantiebestemmingen van Nederlanders wanneer de prijs van vliegtickets, autohuur en hotels het laagst is. Wie naar Thailand wil vliegen kan het best 29 weken voor vertrek boeken. Voor Spanje en Italië is vier weken voor vertrek echter het beste moment. En wie denkt bij een budgetmaatschappij altijd het goedkoopst uit te zijn, kan beter toch nog even het juiste moment van boeken te checken.
Big data geeft inzicht in klantbehoeften
Skyscanner maakt slim gebruik van een klein deel van de mogelijkheden die big data bieden. 70 procent van IT-managers denkt dat de inzet van big data cruciaal is voor succes in de toekomst. 53 procent verwacht concurrentie van startups die in grote mate leunen op big data. 65 procent van de bedrijven denkt dat niet tijdig inbedden de concurrentiepositie schaadt.
Marketing draait meer en meer op het slim combineren van verschillende datastromen en -bronnen. Organisaties die hiermee aan de slag gaan kunnen vrij nauwkeurig het optimale moment bepalen om contact te zoeken en een aanbieding te doen. Want als we prijzen kunnen voorspellen, waarom klantbehoeften dan niet?

Wie is je klant? Welke behoeften, interesses en opinies heeft hij of zij?
Wat is big data?
Volgens Wikipedia spreekt men van big data wanneer men werkt met een of meer datasets die te groot zijn om met reguliere databasemanagementsystemen onderhouden te worden. De hoeveelheid data groeit exponentieel doordat consumenten zelf steeds meer data opslaan in de vorm van bestanden, foto’s en films (bijvoorbeeld op Facebook of YouTube). En doordat er steeds meer apparaten zelf data verzamelen, opslaan en uitwisselen (internet of things).
Het analyseren van deze data speelt een steeds grotere rol en vormt een steeds grotere uitdaging. Het misverstand is vaak dat dit alleen kan met peperdure systemen en zeer uitgebreide rapporten. Goed nieuws: dat kan wel, maar het hoeft zeker niet.
Hoe draagt big data bij aan verkopen?
Data-analyses hebben tot doel toekomstig gedrag van klanten te voorspellen. Zodat daar op in kan worden gespeeld. Hoe beter de voorspelling, hoe beter het resultaat. De voorspelling, lees betrouwbaarheid en nauwkeurigheid, wordt beter naarmate de hoeveelheid data toeneemt. De meeste analyses met (big) data naar klantgedrag zijn in feite regressieanalyses. Doel is de voorspellende waarde van (verschillende) data vast te stellen om zo de variabelen te vinden op basis waarvan het koopgedrag van de klant kan worden voorspeld.
De vergelijking die deze voorspelling weergeeft wordt een algoritme genoemd. En het maken van zo’n algoritme vraagt niet om peperdure tools, maar om inzicht in verbanden tussen data. Hieronder een grafische weergeave van een regressieanalyse.
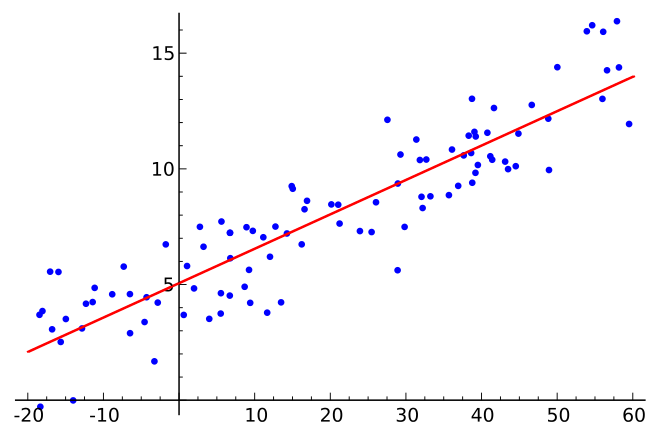
Grafische weergave regressienalyse
Big data laat verbanden zien
Een variant van de regressieanalyse is de Market Basket-analyse. Hierbij wordt bijvoorbeeld een verband gelegd tussen producten in een (digitaal) winkelmandje. Als iemand product A in het mandje stopt, hoe groot is dan de kans dat ook product B wordt gekocht? Of in bredere zin: als iemand X heeft gedaan, hoe groot is de kans dat hij of zij ook Y wil?
Hoe meer gegevens, hoe beter je op basis van gedrag in het verleden de juiste voorspellende factoren kun aanwijzen. En hiervoor vergelijkingen (algoritmes) kunt maken om te voorspellen waar een bepaald type vakantieganger wel of niet op zijn plaats is.
Het voorgaande laat zien dat je in staat moet zijn de volgende taken uit te voeren om te profiteren van big data:
- gegevens verzamelen en analyseren
- algoritmes ontwerpen om tot relevante (voorspellende) informatie te komen
- de informatie omzetten in beslissingen en acties
De start met big data hoeft niet ‘big’ te zijn
Hoe kun je beginnen met big data of je bestaande activiteiten verbeteren? Denk groot, begin klein! Vraag je af aan welke inzichten je nu concreet behoefte hebt om beter te voorzien in de behoeften van je klant. En als je nog moet starten: begin met één onderdeel. Bijvoorbeeld op welk moment een e-mail met aanbieding tot de hoogste conversie leidt. Welke informatie heb je dan nodig en uit welke combinatie van gegevens kan die komen? Begin eens met de tools en data die voorhanden zijn. Rome is ook niet in één dag gebouwd!

Begin te bouwen aan je big data
Meer databronnen, meer context
De meeste organisaties hebben geen uitgebreid netwerk aan platformen. Dat hoeft ook niet. Er zijn meer bronnen beschikbaar dan men vaak denkt. Zoals bijvoorbeeld het CBS (met databank Statline), het SCP, sociale media en websites (met webscraping). Daarnaast heb je zelf vaak meer data dan je denkt: transactiedata, klantdata, bedrijfsdata, marktonderzoek, webanalytics, et cetera. Waar nodig kan dit nog verrijkt worden met GIS-data uit externe bronnen.
Door de combinatie van verschillende databronnen biedt big data contextinformatie. Het biedt inzicht in waar de klant was, met wie, wanneer, waarom, etc. Je krijgt als het ware een beeld van het hele sociale netwerk, opinies, interesses en (inter)acties van de klant. Met deze inzichten kun je gericht waarde toevoegen op elk gebruiksmoment.
Data verzamelen en social listening
Even terug naar het voorbeeld aan het begin. Stel je verkoopt vakanties. Je wilt je klanten op tijd, volledig maar niet te vaak informeren over actualiteiten. Bijvoorbeeld over het weer en activiteiten op hun bestemming. De vraag is wie welke informatie hierover interessant vindt en op welk moment. Hiervoor kun je gegevens van sociale media, sitebezoek en vragen aan je klantenservice combineren.
Vanuit sociale media wordt duidelijk welke vragen over het onderwerp worden gesteld, wanneer en hoeveel. Tegelijk meet je wie de pagina’s binnen je site hierover bezoekt en wanneer hij of zij dat doet. Tot slot kijk je welke klant(groep)en vragen stellen over het onderwerp bij de klantenservice.
Berg gegevens wordt relevante informatie
Om tot goede algoritmes te komen zijn allereerst veel data nodig, maar bovenal systemen die in staat zijn de verschillende soorten datastromen te combineren en te analyseren. Van oudsher zijn veel CRM systemen voornamelijk gericht op dataverzameling en opslag van door gebruikers ingevoerde data. Dat is echter nog maar het begin. Het grote verschil wordt gemaakt door systemen die erin slagen via slimme algoritmes data om te zetten in bruikbare informatie.
Het CRM-beleid moet een slag maken van ‘opslaan van data’ naar ‘structureren, combineren en analyseren van data’. Deze beweging is al enig tijd zichtbaar in de markt. Met groepen aanbieders in drie disciplines die naar elkaar toe bewegen:
- CRM-aanbieders als Oracle en Salesforce die komen vanuit een focus op dataverzameling- en opslag
- partijen als Hubspot en Marketo. Die op basis van geregistreerde contactmomenten met de klant automatisch persoonlijke content en berichten maken
- social media monitoring tools (komen verderop aan bod)
Elk van de hierboven genoemde aanbieders is bezig ook de andere disciplines in zijn tool te integreren. Het is echter nog wachten op een tool die de drie disciplines combineert. Zodat het op grote schaal analyseren van big data ook voor andere organisaties dan Facebook en Google binnen handbereik komt. Met de lancering van haar nieuwe platform heeft Falcon.io hierin onlangs weer een stap gezet.
Sleutel ligt in structureren
Uit voorgaande blijkt dat vaak meer data beschikbaar is dan organisaties zich realiseren. De sleutel ligt letterlijk in structureren van die data. Dat structureren kent twee stappen:
- De data in hetzelfde format zetten. Dit hoeft niet ingewikkeld te zijn, dikwijls wordt een datadump gemaakt vanuit diverse bronnen in een csv-file en geïmporteerd in Excel
- De volgende stap is het koppelen van de data via een unieke sleutel. Een voorbeeld kan de Facebook-gebruikersnaam zijn als je data van sociale media en je CRM-systeem wilt combineren. Op die manier worden social media activiteiten aan de juiste klant in het CRM-systeem gekoppeld
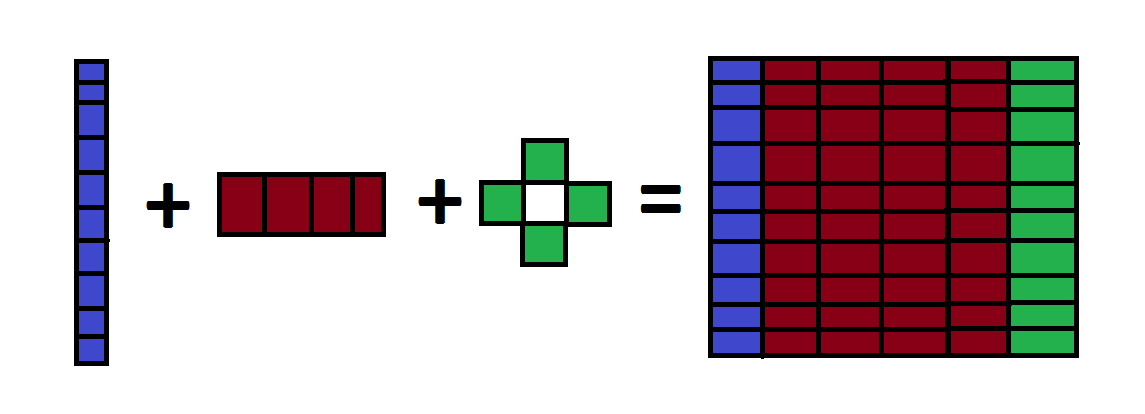
Big Data analyse start met data structureren in één format en één unieke sleutel
Structureren wordt automatiseren
Het structureren van data kan handmatig. Dat is echter, zeker bij grotere hoeveelheden of wanneer de data vaak wordt vernieuwd, een tijdrovend proces. Gelukkig zijn er diverse tools die daarbij ondersteunen.
Laten we het voorbeeld van het weer en de activiteiten op de vakantiebestemming erbij pakken. Met Import.io kun je webpagina’s (deels) ‘schrapen’ en omzetten en data(tabellen). En met Hootsuite (gratis), Coosto en Tracebuzz kun je sociale media monitoren op berichten en vragen over ‘weer en activiteiten op vakantiebestemmingen in het algemeen of specifiek op bestemming X. Voor analyse van het verkeer op je site is Google Analytics prima geschikt. En vanuit al deze tools kun je data als csv-file exporteren om de data te koppelen.
Is dit dan al big data? Zeker, want je combineert drie verschillende datasets, die samen te groot zijn voor een database. Zoals gezegd: Big Data hoeft helemaal niet ‘big’ te zijn. Google en Facebook doen eigenlijk hetzelfde, maar dan met heel veel data uit veel bronnen en in hoge mate geautomatiseerd. Uiteraard zijn er diverse partijen die ook jouw proces (deels) kunnen automatiseren. Dit handmatige voorbeeld gebruik ik om het proces en de denkwijze rondom Big Data te illustreren.
Patronen herkennen en algoritmes opstellen
De volgende stap is op zoek te gaan naar patronen in de data die de benodigde informatie leveren. Is er een patroon te ontdekken in de berichten over ‘het weer’ en ‘vakantieactiviteiten’ op sociale media, demografie en geografie van bezoekers op je site en de kenmerken van klanten die zich melden bij de servicedesk?
Op basis daarvan kun je een algoritme bouwen die zegt wie, waneer, welke informatie wil ontvangen over weersomstandigheden en mogelijke vakantieactiviteiten. Of wat de inhoud van een blog op je site kan zijn om die groep te trekken. En wat dan het beste moment is om dat blog te plaatsen. Herhaal dit voor een aantal andere onderwerpen en je kunt wellicht een algemener algoritme ontwikkelen voor het omgaan met actualiteiten over vakanties in het algemeen.
De juiste bronnen en mensen combineren
Het ontwikkelen van algoritmes start met combineren van data. Dat kan handmatig en is tijdrovend. Voor een robuuste regressieanalyse (lees: een analyse met veel voorspellende waarde) zijn veel en actuele data nodig. Automatiseren heeft uit oogpunt van effectiviteit en efficiëntie vaak de voorkeur.
Juist het geautomatiseerd combineren van de verschillende bronnen is een uitdaging en daarin patronen is een uitdaging. Om te beginnen omdat datastromen uit verschillende formats moeten worden gecombineerd. Wie een beetje kennis van programmeren heeft, kan voor het geautomatiseerd combineren van gegevens bijvoorbeeld gebruik maken van de open source programmeertaal Python. Daarnaast is voor het uitvoeren van (regessie)analyse en opstellen van (voorspellende) algoritmes kennis van statistiek nodig. Waarbij ook ervaring met het onderwerp nodig is om bepaalde patronen te kunnen duiden. Mensen die hiermee aan de slag gaan hebben daarom bij voorkeur kennis van:
- Programmeren
- Statistiek
- Het onderwerp waarop de analyse betrekking heeft
In de praktijk betekent dit dat je dikwijls op zoek moet naar ‘het schaap met de vijf poten’. Vaak gaat het zoeken naar algoritmes beter wanneer je een team formeert dat al deze kwaliteiten combineert:
- Betrek specialisten die het onderwerp en/of de markt kennen. Zonder die kennis is het heel lastig data te duiden en op waarde te schatten.
- Neem vrijheid en tijd om te experimenteren met data om patronen te ontdekken en je ideeën statistisch te (laten) checken
- Begin klein en gebruik verschillende bronnen, juist om meer inzicht te krijgen in de manieren waarop dat (handmatig) kunnen worden gecombineerd
Daarnaast maakt ook visualisatie van de data vaak veel duidelijk. Met de Google Charts Api kun je gegevens neerzetten in grafieken, diagrammen en kaarten om zo meer meer in- en overzicht te creëren.
Juiste data en mensen combineren voor nieuwe inzichten
Voorspellende waarde voorspellen
Stel je hebt een algoritme gevonden, bijvoorbeeld via een Market Basket-analyse. Nu wil je weten of je idee klopt. Dit kun je op verschillende manieren testen:
- In de praktijk: je past het nieuwe algoritme at random toe op de helft van de digitale klantcontacten en kijkt of het leidt tot een toename van de conversie
- Vooraf: als je beschikt over voldoende historische data kun je het algoritme op de data over een bepaalde periode loslaten en vervolgens kijken of de voorspellingen die hieruit voortkomen overeenkomen met het patroon in data in de periode daarna.
Op basis van deze gegevens kan het algoritme worden verfijnd en aangescherpt.
De website weet het cijfer voor je vakantie al
Er komt steeds meer informatie beschikbaar om acties en beslissingen op te baseren. Door het uitwisselen en razendsnel analyseren van data uit verschillende bronnen is in no-time bekend of een product (bijvoorbeeld een vakantie) past bij het profiel van de persoon. En daarmee met welk cijfer de vakantie bij terugkomst wordt beoordeeld.
Nu gaan we nog af op beoordelingen van anderen met wellicht afwijkende eisen, verwachtingen en interesses. Straks zet de site ons eigen profiel centraal en maakt alvast de beoordeling voor ons. En kunnen we al tijdens het kiezen van onze bestemming zien met welk cijfer we de vakantie achteraf gaan waarderen. Fijne vakantie.

Digitaal volwassen worden ☆ ESG & CSRD ☆ Meer impact vanuit thought leadership ☆ Ondersteuning van een ervaren digital marketeer, trainer, spreker en auteur. Naast eigenaar van NickLink en MoreelLeider.nl ben ik partner bij Sky Dust, dat organisaties klaar maakt voor ESG met behulp van AI. Als examinator bij de Nederlandse Marketing Associatie (NIMA) beoordeel ik digitale businessplannen en verbeter ik de marketingervaring in de markt. Voor Hogeschool Windesheim train ik studenten in digital marketing, business innovation en leadership Ik ben een gecertificeerd docent, auteur, spreker en trainer. Mijn specialismen zijn: strategie, data, AI, optimalisatie, ethiek en leiderschap. Wil je ook duurzaam digitaal volwassen worden? Neem contact met me op.
1 Reactie
Plaats reactie
Je moet ingelogd zijn op om een reactie te plaatsen.
Hey Nick, leuk artikel.
Zelf gebruik ik al Google Analytics, maar met de andere tools heb ik nog geen ervaring. Welke (gratis) tools zijn volgens jou het beste om data te verzamelen? Is het beter om wat geld te investeren in een betalende tool, of zijn de gratis (goedkope) ook betrouwbaar en handig? En voor social media monitoring?
Bedankt alvast