Zo werken die nieuwe creatieve AI-systemen
Waarom de nieuwe text-to-image tools ontwerpers en digitale creators in extase brengen.
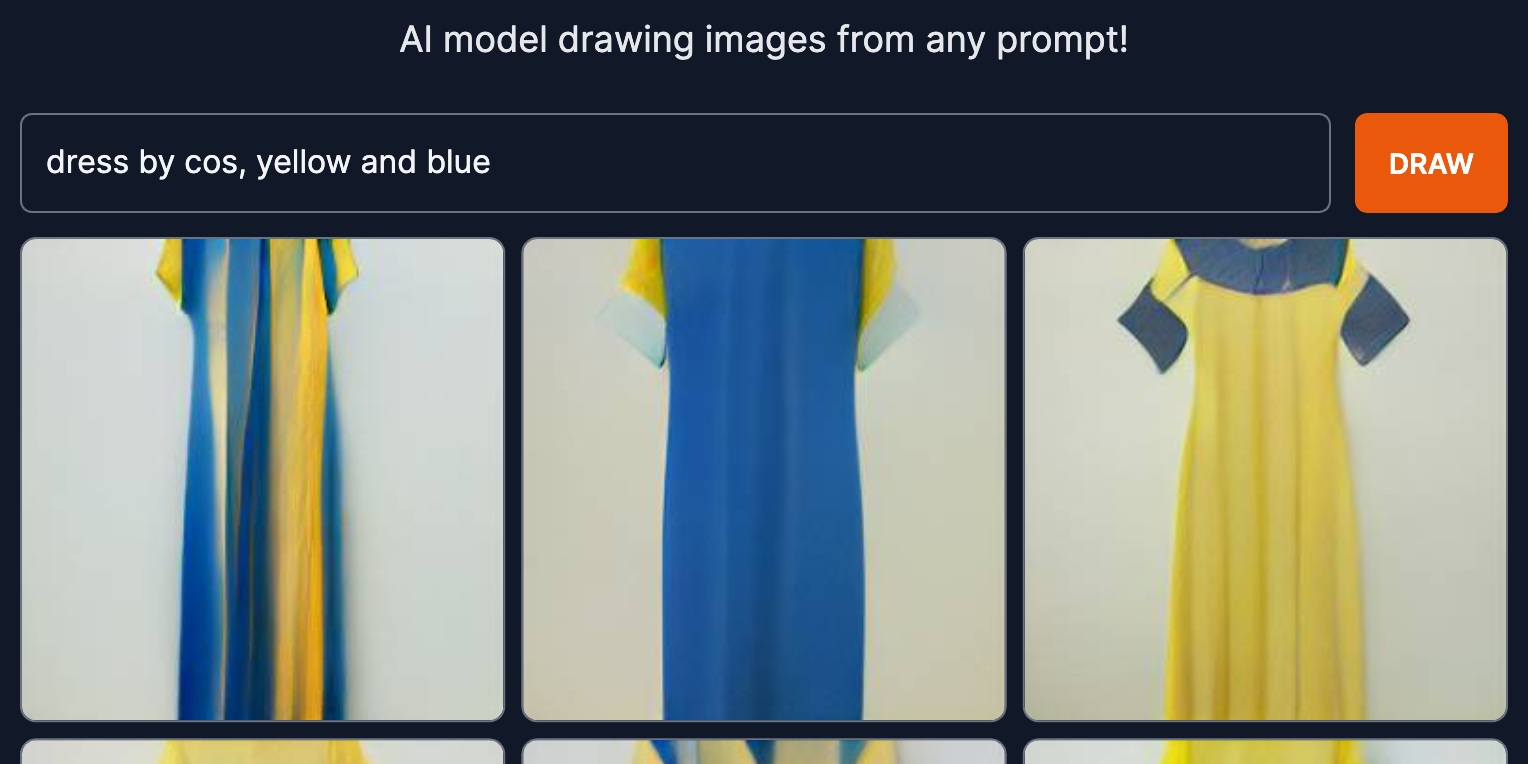
‘Stel je voor dat je de Google zoekbalk gebruikt alsof het Photoshop is – dat is DALL-E.’ Zo legde iemand laatst text-to-image (TTI) toepassingen uit. Ze hebben namen als DALL-E (OpenAI), Imagen (Google), MidJourney en Craiyon. Het is een vorm van kunstmatige intelligentie waarbij je puur en enkel door een regel tekst in te voeren, een compleet beeld kunt laten genereren – in de stijl die je maar wilt: Picasso, Polaroid of 4K.
Hoe de technologie achter text-to-image precies werkt leg ik in dit artikel uit. Je leert waarom dit nieuwe ambacht (of kunst) ‘prompt engineering’ heet. Ook lees je wat zowel negatieve als positieve implicaties van deze technologie zijn. Een echte explainer dus, met tools om het direct eens zelf uit te proberen.
Wat is text-to-image?
De technologie achter deze kunstmatige beeldengeneratoren wordt text-to-image genoemd. Om tot de huidige state-of-the-art te komen, zijn een aantal doorbraken belangrijk geweest, zo vertelt Vox in deze geweldige explainer video (aanrader!).
Een van die doorbraken, gedaan in 2015, heet ‘automated image captioning’. AI-modellen bleken vanaf dat moment niet alleen vrij goed in het detecteren van objecten en figuren in afbeeldingen, ze konden er nu ook beschrijving bij geven. Denk ‘mensen die met een bal spelen op het strand’. AI-onderzoekers dachten: wat nu, als je dat omdraait? Text-to-image als idee was geboren.
Hoe werkt text-to-image (TTI)?
Om de technologie te laten werken, voeren makers van TTI-toepassingen een duur en zwaar op rekenkracht leunend proces uit. Om met de woorden van The Economist te spreken: deze AI-toepassing bouw je niet op je zolderkamer.
Voordat de training begint heeft het team miljoenen beelden van het web moeten scrapen, met bijbehorende beschrijvingen en de alt text (die in HTML de afbeelding beschrijft). Vervolgens wordt al die data – beeld en tekst – ergens opgeslagen. Met de data ter beschikking, kan het ontwikkelen van een TTI-toepassing beginnen. Daarvoor zijn nog een aantal stappen nodig. Dit is hoe Vox ze uiteenzet:
- Training
- Deep learning
- Latent space
- Diffusion
- Output
1. Trainen
Bij het trainen kijkt de computer naar de kleurwaardes van de pixels en leert daarvan welke afbeeldingen bij bepaalde kleuren en kleurpatronen horen. Vervolgens legt het de relatie met de teksten die daar aan gekoppeld zijn. Het model toetst zichzelf in de volgende stap door niet naar de afbeelding te kijken, maar puur naar de pixelwaarden. Daarmee doet het een voorspelling van wat er in het beeld te zien is. Resumerend: eerst doet het systeem een tekstvoorspelling en pas daarna wordt de actual tekst getoond. Is de score beter dan bij de vorige voorspelling, dan leert het model daar van.
2. Deep learning
Om te leren – het model te trainen- wordt deep learning gebruikt. Dit is een vorm van machine learning die werkt met neurale netwerken. Je kunt dit zien als een netwerk van meerdere parallelle lagen die worden gebruikt om informatie door te geven tussen de verschillende lagen. Die informatie bevat herkende patronen, trainingsgegevens, scores en voorspellingen.
3. Latent space – recept voor afbeeldingen
Met alle informatie, patronen en koppelingen die het deep learningproces heeft opgeleverd, moet het TTI-model nu de beelden ‘mappen’ in een denkbeeldige ruimte (de ‘latent space’).
En nu wordt het pas echt ingewikkeld. Denk even aan een specifiek punt of cluster in een meerdimensionale ruimte die hoort bij ‘aardbeien’. Er is een ander punt voor ‘1960’, weer een andere voor ‘Obey’ en een vierde voor ‘kalligrafie’. Er is er een voor ‘sneeuw’, een voor ‘schoen’ en waarschijnlijk bevindt het punt voor ‘sneeuwschoen’ zich ergens tussen die twee.
Een TTI-model gebruikt honderden dimensies en kan met miljarden parameters overweg. Als je hier een ding van moet onthouden: dit kan een mens vrijwel niet goed bevatten of onthouden, maar een computer wel. Zoals Vox het uitlegt: elk punt in deze ruimte kan een recept zijn voor een mogelijke afbeelding. Met de door jou ingevoerde tekst prompt, navigeer je het systeem naar de juiste plek in die space, de ruimte.
4. Diffusion
Voordat het uiteindelijke beeld gegenereerd wordt, vindt er nog ‘diffusion’ plaats. Hierbij wordt een beeld van lage resolutie met veel noise opgebouwd. Dit gebeurt laagje voor laagje totdat het lijkt op het beeld dat we ingaven in de tekst. De laagjes worden opgebouwd aan de hand van die punten uit de latent space, met bijbehorende patronen van pixelwaarden – het recept, herinner je je nog?!
5. Output
Nu is het TTI-model klaar om een ‘selfie van een tiener in de stijl van Picasso’ op meerdere manieren op te bouwen. Net zo lang tot een ander deel van het systeem een goede beoordelingsscore geeft. Die score is weer gebaseerd op de inputbeelden waarmee het model werd getraind.
Het is dankzij diffusion dat je vrijwel nooit twee keer een identiek, zelfde beeld krijgt. Er zit zeker ook een bepaalde randomness in het proces. De beelden waarmee het systeem is getraind, hoe de latent space is gevormd en hoe de semantische ‘map’ is gemaakt (met hoeveel parameters het model kon werken), zijn van invloed op hoe het model beelden genereert.
These AI systems has seen much more than us.
Dit zegt een AI’er in de Vox-video. Maar wees gerust: deze AI-systemen zijn niet creatiever of slimmer dan wij. Ze hebben alleen een groter referentiekader om uit te putten dan een mens ooit zou kunnen.
The Economist schrijft dat men op een gegeven dacht dat meer data geen beter functionerende modellen zou opleveren. Dat blijkt echter wel het geval. Dat wil niet zeggen dat we dat ook maar rücksichtslos moeten doen. Ten eerste omdat dat voor de resources op onze planeet onverstandig is, maar ook omdat dat iets anders gevaarlijks oplevert. Maar daarover verderop meer…
Wat zijn de voor- en nadelen?
Bias
Volgens Casey Newton van Platformer hebben er nu een paar duizend mensen toegang tot DALL-E2, waar er iedere week 1000 bij komen. Je moet volgens hem een content policy document tekenen wil je DALL-E gebruiken. Zo mag je bijvoorbeeld het woord ‘shooting’ niet gebruiken en geen beelden genereren om mensen mee te misleiden (denk aan deepfakes).
Tot voor kort was het niet mogelijk om afbeeldingen te genereren van personen en menselijke gezichten. Dit vanwege restricties die waren ingesteld door de eigenaren. Vooral dankzij die bias: de onderliggende beeld- en tekstmodellen zijn gebaseerd op automatisch gescrapete foto’s en bijschriften van het internet. Daardoor sluipen seksisme, racisme, stereotyperingen en andere vooroordelen naar binnen. Typ je verpleegkundige in dan krijg je een vrouw en bij CEO een man. Wil je een beeld van een gevangene … je raadt het waarschijnlijk al.
Totdat vorige week iemand op Linkedin het volgende beeld plaatste:

Ruimte en plaatsing van objecten
De synthetische afbeeldingen zijn soms perspectivisch off en ook klopt de positie van objecten ten opzichte van elkaar niet altijd.
Handig voor brainstorms en visueel outside-the-box denken
Voordelen zijn dat het je helpt met creatief brainstormen en kan het gegenereerde beeld als visuele check fungeren: sluit ik met mijn werk aan bij bestaande percepties en beelden rondom dit onderwerp?
Wie doen er al iets mee?
De Nederlandse publieke omroep KRO-NCRV heeft een visuele podcast ontwikkeld voor dove en slechthorende kinderen, waarbij het met TTI-beelden aan de podcast toe hebben gevoegd. Zo zijn er ‘drie afleveringen van de populaire kinderpodcast Toen was ik 12 toegankelijk gemaakt met behulp van kunstmatige intelligentie (AI). De AI vertaalt de bestaande audio-content van Toen was ik 12 naar creatieve beelden. Met de vodcast wil KRO-NCRV meer media toegankelijk maken voor mensen met een beperking en meer kennis opdoen van de mogelijkheden van AI-systemen om automatisch content te genereren.’
Casey Newton beschrijft een artiest die DALL-E gebruikt om augmented reality filters voor social apps te genereren. Ook zou een chef in Miami text-to-image gebruiken voor inspiratie om zijn borden op te maken.
Synthetische Cosmo-cover
De nieuwe Cosmo heeft een synthetisch beeld op de cover, waar ook al direct de nodige kritiek op kwam:

Text-to-music
Het hoeft niet per se meer om afbeeldingen te gaan. Zo trainde Reeps One, een Britse componist, een model met zijn eigen human beatbox-achtige vocalen, zodat hij nu een drumcomputer heeft die is gebaseerd op zijn eigen stem. Om zijn signature muziek te maken heeft ‘ie z’n stem dus niet meer nodig.
Text-to-text
Een op GPT3-gebaseerde schrijftool genaamd Co-Author leert deels op dezelfde manier teksten genereren als TTI, alleen zou je de toepassing hier text-to-text kunnen noemen.
Waar kunnen we het verwachten?
Vorige week liet ik aan een fotoredacteur van NRC zien wat je allemaal met DALL-E kunt. Dat deed ik aan de hand van DALL-E2’s showaccount op Instagram. De redacteur voelde zich geenszins bedreigd. Sterker nog, ze zag allerlei ‘illustrationele’ (mijn woord) toepassingen, voor bij essays, what-if verhalen en voor beelden bij meer abstracte (vaak digitale) onderwerpen zoals crypto, cybercrime maar ook voor #metoo.
Youtuber/designer Linus Bowman analyseert dat TTI-beelden nu allemaal nog een beetje vervreemdende onderwerpen hebben en absurd zijn. De nieuwigheid zal volgens hem snel weg ebben. Zijn observatie: de meest populaire prompts eindigen met ‘in de stijl van kunstenaar x’ (of ‘designer y’). Een ander vermoeden van Bowman is dat mensen hun ‘prompts’ voor zich houden, en dat zij het ‘engineeren’ ervan tot een ware kunst (of ambacht) proberen te verheffen.
Mediahuis Change Director Ezra Eeman plaatste deze conversation piece op Linkedin:

Casey Newton schrijft:
It’s often the case that, when a new technology emerges, we focus on its happier and more whimsical uses, only to ignore how it might be misused in the future.
Waar moeten we bang voor zijn?
“Design is intelligence made visible,” zei iemand ooit. Nu we kunstmatige intelligentie kunnen inzetten om visuals te maken, verliezen kunstenaars, illustratoren en (grafisch) ontwerpers dan nu hun alleenrecht op ontwerpen? Moeten ze vrezen voor hun baan? Nee. Althans, niet degenen met een eigen signatuur, visie en mening over wat goed beeld is. Er is meer nodig voor creativiteit dan fotorealistische beelden genereren.
Wie krijgen er last van deze mogelijkheden?
Volgens Bowman moeten we onthouden dat disruptieve technologie (die dit ook wellicht is) altijd aan de onderkant van de markt binnenkomt. Designers die templates maken, logo’s ontwerpen of designs omzetten naar verschillende systemen – zij moeten oppassen of nieuw werk zoeken. Text-to-image bedreigt waarschijnlijk ook de stockfoto, maar daar zullen de meeste ontwerpers niet rouwig om zijn. Met deze AI-toepassing kun je immers iedere keer weer unieke beelden genereren en gebruiken.
Vooral werk dat visueel inwisselbaar is, zal hiermee concurrentie krijgen. Visual designers hoeven dus niet direct bang te zijn.
Waar onderzoekers echter voor waarschuwen is het feit dat deze grote foundation modellen alleen nog maar door grote bedrijven kunnen worden gebouwd, omdat ze duur zijn, veel data nodig hebben en veel rekenkracht. Zelfs de grootste universiteiten ter wereld zijn bijna niet meer in staat om een aantal Chinese techbedrijven, Google, OpenAI of Meta bij te benen op dit vlak.
En copyright dan?
Alle beelden worden ter plekke gegenereerd en van plagiaat is dan geen sprake. Casey Newton schrijft over DALL-E, bijvoorbeeld als je beelden met Superman of Mickey Mouse zou maken: ‘It’s not entirely clear whether using AI to generate images of protected works is considered fair use or not, I’m told’.
Bij de tool Craiyon (die open source, gratis en vrij toegankelijk is) staat het volgende over gebruik van de beelden: ‘Can I use the images generated through craiyon? Yes, feel free to use them as you wish for personal use, whether you want to share them with your friends or print on a T-shirt. For commercial use, please contact us.’
Zelf proberen?
Craiyon is de tool voor iedereen die geen toegang heeft tot DALL-E, MidJourney of Imagen. (Het heette tot een week geleden nog DALL E mini!)
Je kunt ook met tools als GauGan2, Snowpixel en NightCafe experimenteren.

Laurens Vreekamp (1980) is journalist, design thinker en oprichter van de Future Journalism Today Academy. Hij werkte als Teaching Fellow bij Google’s News Lab en was docent-onderzoeker UX Design aan de Hogeschool Utrecht. Volg een introductietraining over AI of boek hem als spreker.
Plaats reactie
Je moet ingelogd zijn op om een reactie te plaatsen.