Van informatie naar dingen: help Google te begrijpen wat er op je website staat

Met schema.org gegevensopmaak help je Google te begrijpen wat er nu eigenlijk op je webpagina’s staat
Zoekmachines zijn onze portaal naar wat er op in het internet te vinden is. Je tikt een zoekopdracht in in Google en die geeft je de 10 meest relevante webpagina’s die antwoord geven op jouw zoekvraag. Fantastisch toch? Google doorzoekt ruim 60 biljoen webpagina’s om antwoord te geven op jouw vraag! Je kunt Google in feite zien als een set formules en algoritmes die enerzijds jouw zoekvraag en anderzijds het web zo goed mogelijk proberen te begrijpen, met als doel een zo relevant mogelijk antwoord te geven op je zoekvraag. Met schema.org-gegevensopmaak help je Google in het begrijpen wat er zich nu eigenlijk op jouw webpagina’s bevindt. In dit artikel leg ik uit wat schema.org-gegevensopmaak is, wat het doet en hoe je het implementeert.
Twee jaar geleden ben ik aan de slag gegaan met de zoekmachineoptimalisatie van Marketingfacts. In dit vierluik vertel ik, als niet-SEO’er, over mijn zoektocht en de kennis die ik daarin heb opgedaan. SEO door de ogen van een online marketeer, dus. Eerder publiceerde ik al ‘Klassieke SEO in een tijd van contentmarketing‘ over het optimaliseren van meta-informatie.
Begrijpen van de vraag
Om zo goed mogelijk antwoord te geven op je zoekvraag, probeert het je zoekvraag steeds beter te begrijpen. Dit doet Google bijvoorbeeld met autocomplete (helpt bij het formuleren van je zoekvraag), voice search, het controleren van spelling- en typefouten en het begrijpen van synoniemen. De Hummingbird-update is ook een belangrijke stap geweest in het beter begrijpen van de zoekmachinegebruiker. Voorheen werd puur naar de woorden in de vraag gekeken, maar nu wordt ook de context meegenomen. Het gaat niet om wat je expliciet intypt, maar om wat je impliciet bedoelt. De zoekmachine probeert daarbij verbanden te leggen, conversaties te begrijpen en complexe vragen te beantwoorden.
Begrijpen van het antwoord
De andere kant van het verhaal is dat Google informatie op het web beter wil begrijpen. Even een stapje terug. Om antwoord te geven op je zoekvraag, indexeert Google webpagina’s. De zoekmachinerobot (spider) brengt hiervoor een bezoek aan de website en wordt deze ingelezen en volgt links om ook andere webpagina’s te ontdekken (crawlen). Webstandaarden zoals HTML helpen zoekmachines te begrijpen welke informatie er op een pagina te vinden is. De eerste zoekmachines, waaronder Altavista en het Nederlandse Ilse, keken alleen naar on-page factoren zoals tekst en de opbouw van de pagina zelf. Daarin keken ze hoe vaak een bepaald woord voorkwam en op welke plaats op de pagina. Google zorgde voor een grote revolutie door niet alleen te kijken naar tekst en aantal woorden, maar ook andere factoren mee te nemen in de beoordeling. De waarde van links is hier de bekendste van. Hiermee kon Google, aan de hand van het aantal inkomende links, veel beter bepalen hoe waardevol een webpagina is.
Van webpagina’s naar betekenis
Tegenwoordig zijn er meer dan 200 factoren (of signals) die meespelen in het rangschikken van websites die het beste antwoord geven op onze zoekvraag. Met Google kunnen we dingen te vinden die ‘we’ als beschaving publiceren. De volgende stap voor zoekmachines is dat ze antwoord geven op vragen waar ‘we’ als beschaving het antwoord op weten. Daarmee gaat de zoekmachine verder dan informatieverwerking: het gaat de betekenis begrijpen. Dat noemen we semantiek, vandaar het semantische web. Onderstaande video legt dit mooi uit:
In het semantische web begrijpen machines en software informatie en kunnen deze informatie met elkaar verbinden. Zo kan informatie van meerdere webpagina’s kan worden gecombineerd om een antwoord te geven om een zoekvraag. Een mooi voorbeeld van een zoekmachine die dit nu al doet is Wolfram Alpha. Het begrijpt wat je zoekt en geeft daar direct antwoord op. Hierbij kan het ook meerdere bronnen combineren.
Voorbeeld:
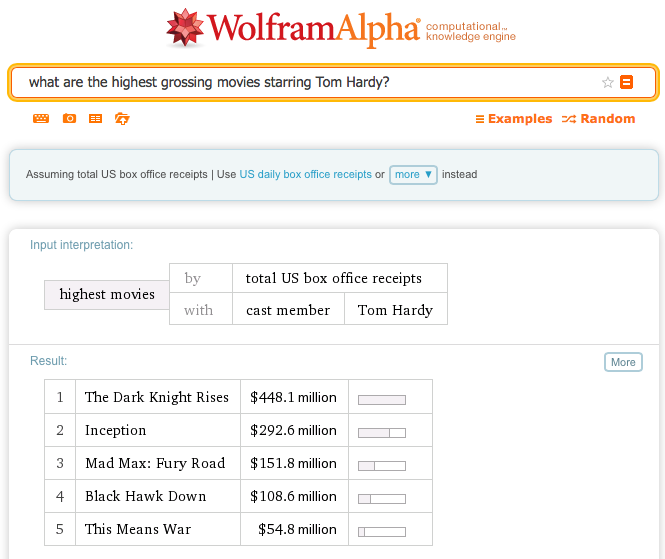
Wil je meer weten of hoe Wolfram Alpha werkt, lees dan de uitleg van Stephen Wolfram himself.
Ook Google probeert steeds meer te begrijpen wat je zoekt. Met de Hummingbird-algoritme-update heeft Google hiermee een stap voorwaarts gezet. Naast context probeert Google de woordbetekenis te begrijpen. Het feit dat Google 15 procent van alle zoekopdrachten nog nooit eerder heeft gezien, geeft wel aan hoe belangrijk het is voor Google om de betekenis van woorden te kennen. Dan is het namelijk niet zo’n probleem meer als je dagelijks zoekopdrachten krijgt die je niet eerder hebt gezien.
Google doet zelf haar best om de betekenis van woorden te begrijpen, maar door gegevens op je website op te maken, kun je als website-eigenaar daar Google ook een handje mee helpen. Voorbeelden van de zoektocht naar betekenis zijn er volop. Zo geeft Google via ‘instant information‘ bij zoekopdrachten naar informatie steeds vaker direct het antwoord zonder de bezoeker weg te sturen van de zoekmachine. Zoek je naar ‘weer in Amsterdam’, dan hoef je niet meer door te klikken naar een website met weerberichten, maar krijg je direct in Google het weer in Amsterdam te zien. Zoek je een muziekvideo dan wordt op de zoekresultatenpagina de video direct ingeladen.
Bovendien houdt Google rekening met meerdere contexten van je zoekopdracht. Wanneer ik bijvoorbeeld op ‘pizza’ zoek, dan serveert (pun intended) Google me zowel informatie als restaurants waar ik pizza kan eten. Voor wat het laatste betreft, toont Google zowel websites waar ik eten kan bestellen als pizzaria’s in mijn omgeving.
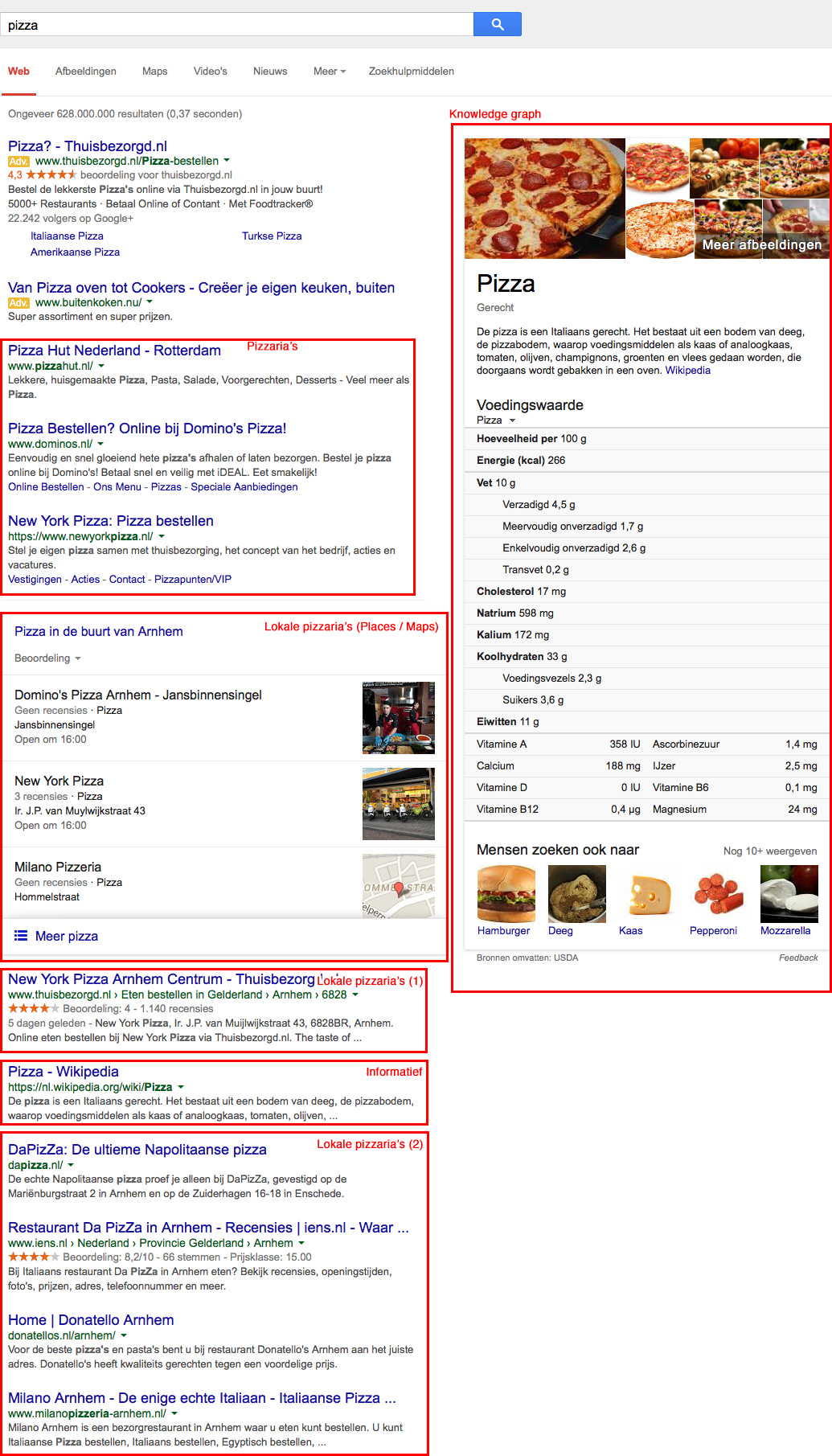
Help Google ‘dingen’ op je website te begrijpen
In bovenstaand voorbeeld kun je zien dat Google al enigszins de context begrijpt van informatie. Om dat te kunnen doen, wil Google ‘dingen’ (mensen, plaatsen, bedrijven, evenementen, etcetera) begrijpen. Google noemt dit de Knowledge Graph. Google zou Google niet zijn als ze zelf software zou schrijven om informatie op het internet te vertalen naar objecten en relaties. Gebruikers begrijpen vaak intuïtief wat een waarde voorstelt, bijvoorbeeld dat een getal een prijs uitdrukt. Zoekmachines hebben hier meer moeite mee.
Een technisch hulpmiddel om zoekmachines content op je website beter te begrijpen, is het toepassen van gegevensopmaak voor het structureren van data. Deze extra opmaak is voornamelijk zichtbaar aan de achterkant van je website en is niet zichtbaar voor gebruikers. Het toepassen van HTML-gegevensopmaak is niet nieuw. Het wordt al enkele jaren toegepast, met technieken als microdata en RDFa. De opmaaktechniek JSON-LD wordt ook toegepast, maar is nog relatief nieuw. Deze verschillende vormen van gegevensopmaak zijn vastgelegd in schema.org, een initiatief van de vier grote zoekmachines Yahoo!, Bing, Yandex en Google.
Op Marketingfacts hebben we 3 hoofdobjecten die we met schema.org hebben getagt: artikelen, reacties en personen (auteurs van artikelen en reacties). Hieronder ga ik deze af.
Artikel
Hieronder is de schema.org-tagging van de artikeldetailpagina (specifiek deze), inclusief de hiërarchie, gevisualiseerd. Het artikel is een contentobject ‘article‘, dat verschillende attributen bevat, zoals een titel, beschrijving en datumnotatie. Het bevat ook enkele onderliggende contentobjecten: een auteur (persoon) en een creativecommonsdeclaratie. De auteur bevat op haar beurt weer een ‘worksFor’ (organisatie).
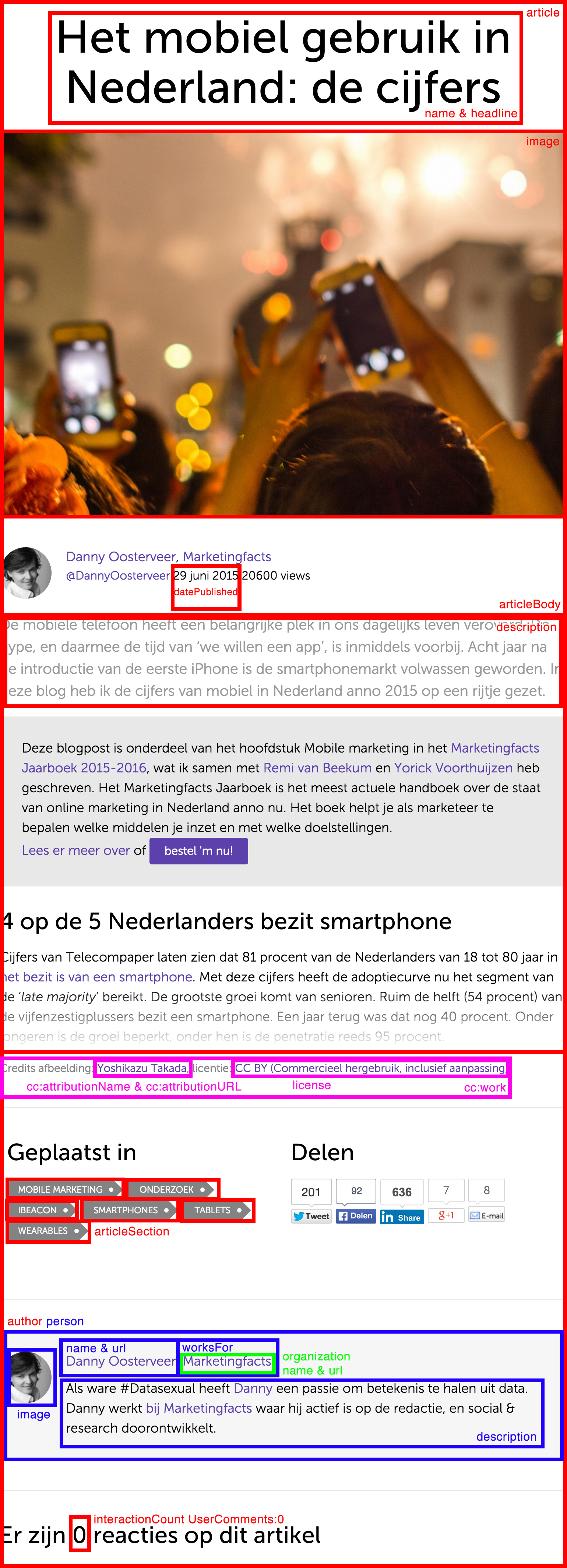
Creative commons declaratie
Het is verrassend moeilijk om goede informatie te vinden over het declareren van creative commons. Het is des te verrassender, omdat dit stukje gegevensopmaak wél zichtbaar is voor de gebruiker. Althans, op de webpagina zelf, maar het effect ervan wel. Wat deze gegevensopmaak doet, is dat het de licentie voor de afbeelding bij de blog declareert.
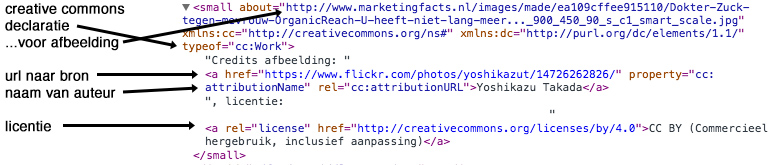
Het resultaat hiervan is dat zoekmachines kunnen bepalen of een afbeelding auteursrechtelijk beschermd is, of dat hij (commercieel) mag worden hergebruikt, of dat hij volledig rechtenvrij is (publiek domein). In Google zie je dit terug wanneer je op afbeeldingen zoekt, naar afbeeldingen die je mag hergebruiken. Voor bij de artikelen bij Marketingfacts maken we vaak gebruik van creative commons gelicenseerde of rechtenvrije afbeeldingen. Daarvoor zoeken we met Google op afbeeldingen en zetten we gebruiksrechten op ‘Gelabeld voor hergebruik’ (dat zijn afbeeldingen die commercieel mogen worden hergebruikt).
Wil je meer weten over hoe je de rechten van afbeeldingen in je webpagina opneemt kijk dan hier op de website van Creative Commons.
Gegevensopmaak zoals Google het ziet
Google ziet de schema.org-gegevensopmaak van de artikeldetailpagina van Marketingfacts als volgt:
|
Article |
|
|
name: |
Het mobiel gebruik in Nederland: de cijfers |
|
headline: |
Het mobiel gebruik in Nederland: de cijfers |
|
image: |
https://www.marketingfacts.nl/wp-content/uploads/images/[…]s_c1_smart_scale.jpg |
|
datePublished: |
2015-06-29T07:00:00+02:00 |
|
articleBody: |
De mobiele telefoon heeft een belangrijke plek in ons dagelijks leven veroverd. De hype, en daarmee de tijd van ‘we willen een app’, is inmiddels voorbij. Acht jaar na de introductie van de eerste iPhone is de smartphonemarkt volwassen geworden. In deze blog heb ik de cijfers van mobiel in Nederland anno 2015 op een rijtje gezet. Deze blogpost is onderdeel van het hoofdstuk Mobile marketing in het Marketingfacts Jaarboek 2015-2016, wat ik samen met Remi van Beekum en Yorick Voorthuijzen heb geschreven… |
|
description: |
De mobiele telefoon heeft een belangrijke plek in ons dagelijks leven veroverd. De hype, en daarmee de tijd van ‘we willen een app’, is inmiddels voorbij. Acht jaar na de introductie van de eerste iPhone is de smartphonemarkt volwassen geworden. In deze blog heb ik de cijfers van mobiel in Nederland anno 2015 op een rijtje gezet. |
|
articleSection: |
Mobile marketing |
|
articleSection: |
Onderzoek |
|
articleSection: |
ibeacon |
|
articleSection: |
smartphones |
|
articleSection: |
tablets |
|
articleSection: |
wearables |
|
interactionCount: |
UserComments:0 |
|
author [Person]: |
|
|
image: |
https://www.marketingfacts.nl/wp-content/uploads/images/[…]s_c1_smart_scale.jpg |
|
url: |
http://www.marketingfacts.nl/profiel/13656 |
|
name: |
Danny Oosterveer |
|
description: |
Als ware #Datasexual heeft Danny een passie om betekenis te halen uit data. Danny werkt bij Marketingfacts waar hij actief is op de redactie, en social & research doorontwikkelt. |
|
worksFor [Organization]: |
|
|
name: |
Marketingfacts |
|
url: |
|
Reactie(s)
Op de artikelpagina staan ook reacties. Ook een reactie is een object, die er als volgt uit ziet (voorbeeld):
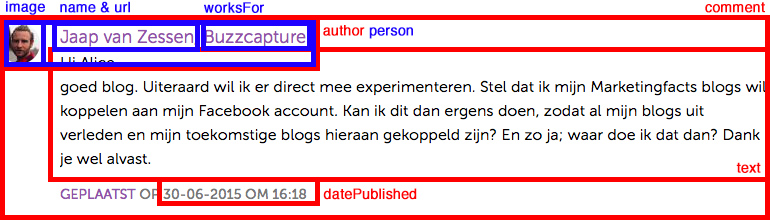
Google ziet deze reactie als volgt:
|
Comment 1 |
|
|
text: |
Hi Alice, goed blog. Uiteraard wil ik er direct mee experimenteren. Stel dat ik mijn Marketingfacts blogs… |
|
datePublished: |
2015-06-30T16:18:54+02:00 |
|
author [Person]: |
|
|
url: |
http://www.marketingfacts.nl/profiel/217400 |
|
name: |
Jaap van Zessen |
|
worksFor [Organization]: |
|
|
name: |
Buzzcapture |
Personen
De auteursprofielen (voorbeeld) bevatten ook gegevensopmaak. Het hoofdobject is de beschrijving van een persoon. De persoon bevat ook nog een nevenobject, de organisatie waar hij of zij voor werkt.
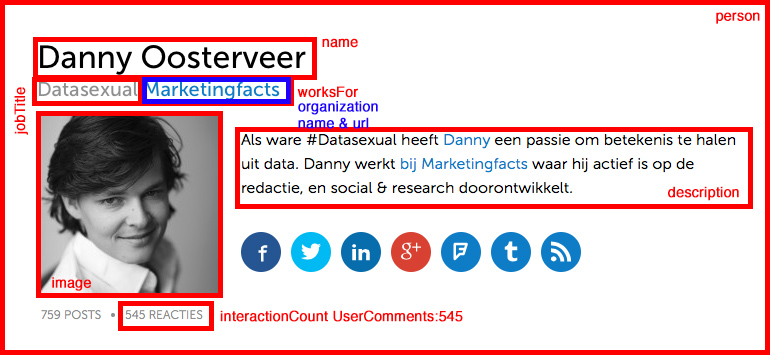
Google ziet een auteursprofiel als volgt:
|
Person |
|
|
name: |
Danny Oosterveer |
|
jobTitle: |
Datasexual |
|
image: |
https://www.marketingfacts.nl/wp-content/uploads/images/[…]s_c1_smart_scale.jpg |
|
interactionCount: |
UserComments:545 |
|
description: |
Als ware #Datasexual heeft Danny een passie om betekenis te halen uit data. Danny werkt bij Marketingfacts waar hij actief is op de redactie, en social & research doorontwikkelt. |
|
worksFor [Organization]: |
|
|
name: |
Marketingfacts |
|
url: |
|
Overige elementen
Organisatie
Je kunt Google ook informeren over je organisatie. Ik leerde pas bij het schrijven van deze reeks over dit type gegevensopmaak. Google heeft vaak even nodig om nieuwe gegevensopmaak op te pakken, dus voor dit type gebruik ik andere voorbeelden.
Met ‘organisatie’ kun je Google onder andere vertellen wat het logo van je website is. De zoekmachine zegt het logo ‘daar waar mogelijk te gebruiken‘: “Markup like this is a strong signal to our algorithms to show this image in preference over others, for example when we show Knowledge Graph on the right hand side based on users’ queries.” Om deze gegevensopmaak toe te passen, declareer je een organisatie om het logo van je website. Binnen dat element tag je vervolgens de canonical-url van je homepage en de url naar je logo.
| Organization | |
| url: | http://www.marketingfacts.nl |
| logo: | http://www.marketingfacts.nl/assets/images/logo.png |
Met ‘organization’ kun je Google nog meer informatie doorgeven over je website, namelijk de links naar je profielen op andere sociale media en telefonische contactgegevens. De laatste passen we op Marketingfacts niet toe, maar als je dat wel wilt, kun je daar hier meer informatie over vinden. Zowel het logo, de telefonische contactgegevens en links naar sociale profielen zegt Google in de Knowledge Graph te gebruiken. Links naar je sociale profielen voeg je toe door simpelweg het attribuut ‘sameAs’ toe tevoegen aan links naar je sociale profielen. De volledige gegevensopmaak van de ‘organisatie’ van Marketingfacts ziet er als volgt uit:
| Organization | |
| name: | Marketingfacts |
| url: | http://www.marketingfacts.nl/ |
| logo: | http://www.example.com/assets/images/logo.png |
| sameAs: | http://twitter.com/Marketingfacts |
| sameAs: | http://www.facebook.com/marketingfacts |
| sameAs: | http://www.linkedin.com/company/marketingfacts |
| sameAs: | http://plus.google.com/+marketingfacts |
Op de zoekresultatenpagina ziet het resultaat er als volgt uit:
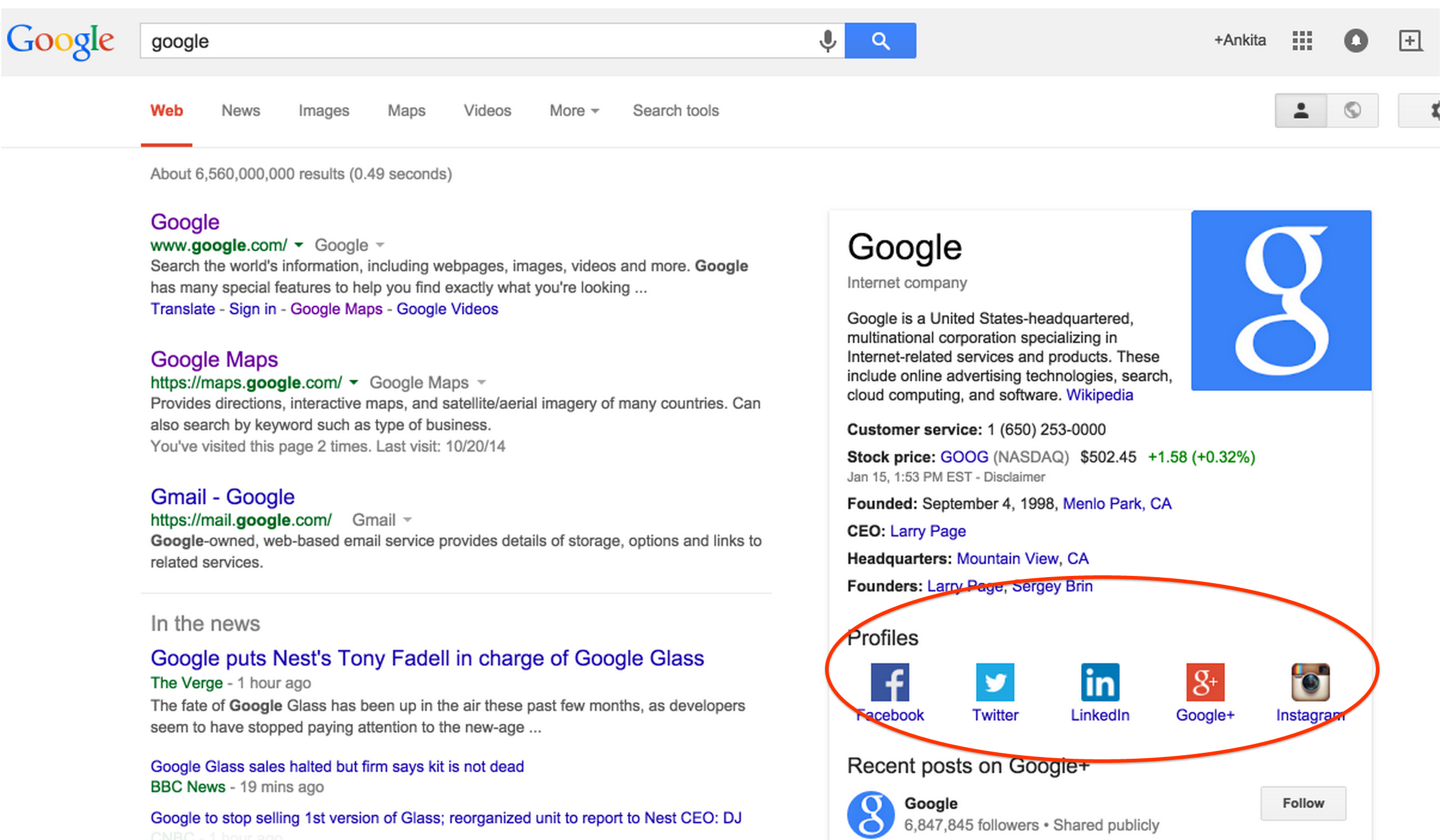
In bovenstaande tabel zie je dat ik ook ‘name’ heb toegevoegd. Dit attribuut gebruikt Google op de zoekresultatenpagina. De naam van de website vervangt hier het uitgeschreven domein. Je ziet op de zoekresultatenpagina dus ‘Google’ in plaats van ‘www.google.com’.
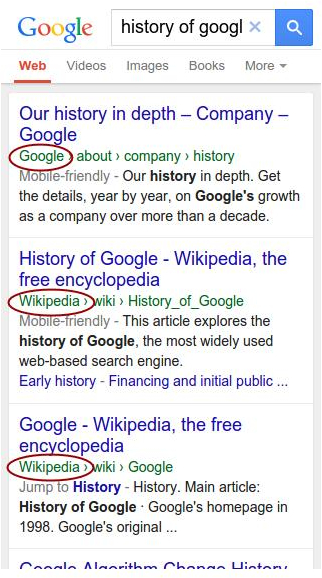
Sitelinks search box
Mogelijk ben je hem zelf al tegengekomen op de zoekresultatenpagina, de zoekbalk op de zoekresultatenpagina. En dan bedoel ik niet de zoekbalk bovenaan, maar die binnen een zoekresultaat. Met deze zoekbalk, die in 2014 het licht zag, kun je zoeken binnen de website van het zoekresultaat. De sitelinks search box ziet er als volgt uit:
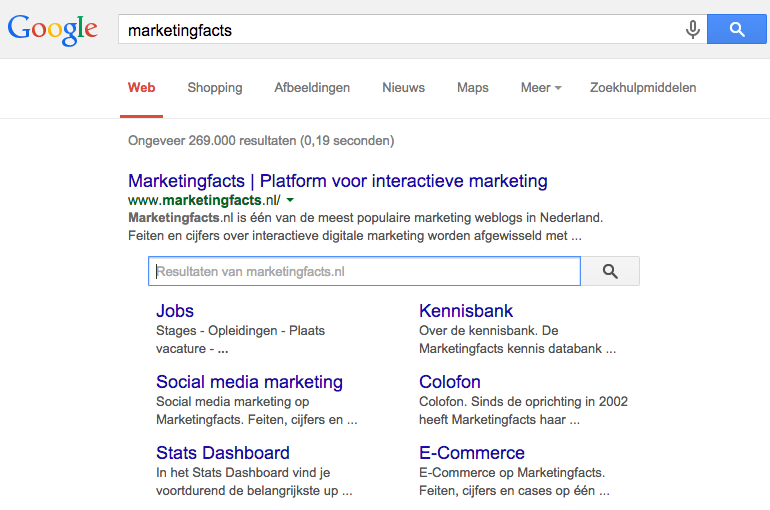
Wanneer je je interne zoekmachine met schema.org-gegevensopmaak structureert en dit wordt opgepikt door Google, kan er direct vanaf dit zoekresultaat op je website worden gezocht. Heb je deze opmaak niet, dan toont Google de zoekresultaten binnen Google zelf. De ‘eigen’ zoekmachine heeft een belangrijk voordeel: daarvan kunnen we de zoektermen inzien. Die van Google krijgen we sinds een tijd al niet meer door. Belangrijk is natuurlijk wel dat je een goede interne zoekmachine hebt die voldoet aan de verwachtingen van de gebruikers. Op Marketingfacts gebruiken we eveneens de zoektechniek van Google met Google Site Search.
Met gegevensopmaak wordt de interne zoekmachine gebruikt:

Heb je die niet, dan toont Google de zoekresultaten binnen de eigen website:
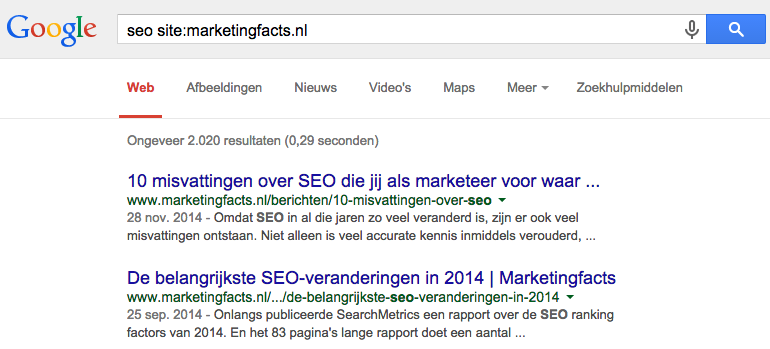
Om dit voor elkaar te krijgen, dienen we enkele gegevens van de zoekbalk van je website te structureren. De html-code vind je hier. Het resultaat, zoals Google dat ziet, zie je hieronder. Het resultaat leest wat minder intuïtief dan de voorgaande objecten. Wat je in feite doet, is dat je Google vertelt dat er een ‘zoekactie’ op je site gedaan kan worden. Bovendien geef je mee dat als externe bronnen gebruikers op je website willen laten zien, ze de zoekwoorden meegeven aan de url zoals die in ‘urlTemplate’ staat.
| WebSite | |
| url: | http://www.marketingfacts.nl |
| potentialAction [SearchAction]: | |
| target [EntryPoint]: | |
| urlTemplate: | http://www.marketingfacts.nl/zoeken?q={q}&utm_source=search&utm_medium=sitelinksearch |
| query-input [PropertyValueSpecification]: | |
| valueName: | q |
Net als voor de ‘Open Search-integratie‘ die ik in mijn eerste artikel bescheef (waarmee gebruikers bijvoorbeeld direct vanuit de browser op je website kunnen zoeken), geef ik ook de Sitelinks Searchbox een ‘utm_source’ en ‘utm_medium’ mee, zodat ik deze in Google Analytics kan onderscheiden.
Niet gebruikt
Er zijn nog een aantal objecten die Google al wel inleest maar die ik niet op Marketingfacts heb toegepast. Even terug in het artikel noemde ik al het vermelden van telefonische contactgegevens. Andere objecten die ik in dit artikel niet behandel zijn breadcrumbs en ‘acties‘. Bovendien zijn er een aantal types die we niet op Marketingfacts hebben en daarom geen onderdeel zijn van dit artikel, te weten: producten, recepten, reviews, events, apps en video’s.
Overzicht van gevonden gegevensopmaak
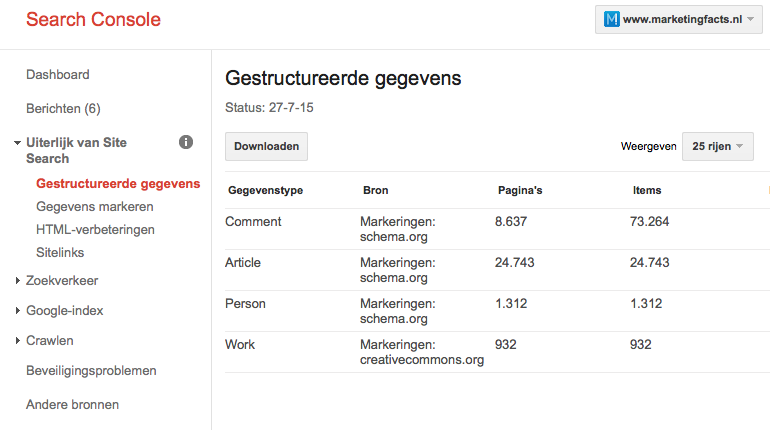
Google Search Console, het hulpprogramma van Google voor website-eigenaren, heeft een functie waarbij je kunt zien welke soorten HTML-mark-up er door Google geïnterpreteerd zijn. Hiervoor ga je naar ‘Gestructureerde gegevens’, onder ‘Uiterlijk van Site Search’. Onder ‘Gegevens markeren’ vind je hulp van Google voor het opmaken van gegevens.
Tips
- Op schema.org vind je uitgebreide documentatie over schema.org-gegevensopmaak. Ik vind de website echter niet altijd even duidelijk in hoe het geïmplementeerd moet worden. Ik zou je adviseren om vooral ook te spieken bij websites die het goed geïmplementeerd hebben, en de testtool van Google te gebruiken.
- Voorbeelden van websites met schema.org gegevensopmaak (heel leerzaam!):
- Artikel: Marketingfacts (analyse)
- Product: adidas (analyse)
- Film: IMDB (analyse)
- Recept: Albert Heijn (analyse)
- Events: Viagogo (analyse)
- App: Google Play Store (analyse)
- Boek: iTunes (analyse)
- Restaurant & reviews: Iens (analyse)
- Video: YouTube (analyse)
- Breadcrumbs: Radboud Universiteit (analyse)
- Om te kijken hoe de tags en de structuur van de tags op je website geïmplementeerd zijn kun je de Structured Data Testing Tool gebruiken
- Google heeft een tool ontwikkeld, Markup Helper, waarmee je stap voor stap schema.org gegevensopmaak kunt toevoegen
- Hier vind je meer informatie over hoe je een creative commons declaratie kan opnemen
- Dit artikel beschrijft nóg uitgebreider hoe je schema.org-gegevensopmaak implementeert en hoe deze wordt getoond door Google
Het effect
Wanneer Google je webite beter begrijpt, heeft het meest zicht op wanneer het relevant is om je website te tonen. Op dit moment weegt het echter nog niet mee in de ranking van Google. Het is echter niet moelijk voor te stellen dat het begrijpen van content en relaties voordelen gaat hebben.
Wat Google al wel doet, is dat het gegevensopmaak gebruikt om zoekresultaten te verrijken op de zoekresultatenpagina. Google noemt dit zelf ‘rich snippets‘. Er zijn al diverse ‘dingen’ waarvoor Google dit toont, zoals recepten, recenties, reviews, evenementen, breadcrumbs, sportwedstrijden, films en boeken.
Voorbeeld: recept
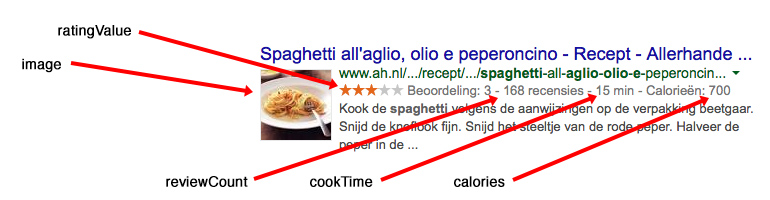
Een voorbeeld om dit te illustreren is een recept van Albert Heijn’s Allerhande:
| Recipe | |
| name: | Spaghetti all’aglio, olio e peperoncino |
| image: | http://www.ah.nl.kpnis.nl/static/recepten/img_004415_445x297_JPG.jpg |
| totalTime: | PT15M |
| cookTime: | PT15M |
| recipeCuisine: | italiaans |
| recipeCategory: | hoofdgerecht |
| recipeYield: | 4 personen |
| ingredients: | 400 g spaghetti |
| ingredients: | 4 tenen knoflook |
| ingredients: | 1 rode peper |
| ingredients: | 150 g olijfolie |
| recipeInstructions: | Bereiden stap voor stap koken print Let op! Je wijkt af van het aantal personen waarvoor dit recept geschreven is. Bereiding, kook- en oventijden en keukenspullen kunnen hierdoor ook afwijken. Lees de tips Kook de spaghetti volgens de aanwijzingen op de verpakking beetgaar. Snijd de knoflook fijn. Snijd het steeltje van de rode peper. Halveer de peper in de lengte en verwijder met een scherp mesje de zaadlijsten. Snijd de peper in dunne reepjes. Verwarm de olijfolie in een steelpan en roer de knoflook en rode peper erdoor. Verwarm het geheel 1-2 min. op matig hoog vuur. De knoflook mag niet kleuren. Giet de spaghetti af en meng de olie met knoflook erdoor. Schep de spaghetti in diepe borden. combinatietip: Lekker met een frisse gemengde salade. print |
| aggregateRating [AggregateRating]: | |
| ratingValue: | 3 |
| reviewCount: | 168 |
| nutrition [NutritionInformation]: | |
| calories: | 700 kcal |
| proteinContent: | 12 g |
| carbohydrateContent: | 72 g |
| fatContent: | 40 g |
| saturatedFatContent: | 0 g |
Van deze gestructureerde gegevens zijn een aantal die Google visualiseert op de zoekresultatenpagina en waardoor je website extra opvalt:
Artikelen
Voor artikelen kan Google de schema.org-gegevensopmaak gebruiken om je artikel als ‘nieuws’ of in een ‘content caroussel‘ uit te lichten. ‘Nieuws’ zijn zeer actuele artikelen die als zodanig als ‘nieuws’ worden uitgelicht op de zoekresultatenpagina. Content carousels zijn relatief nieuw en worden gebruikt om meerdere resultaten te groeperen voor zoekopdrachten naar actuele onderwerpen. Google specificeert de volgende benodigde en optionele tags die het gebruikt voor het uitlichten van artikelen:
| Property | Type | Description |
|---|---|---|
| headline (required) | Text | The headline of the article |
| image (required) | URL | A URL, or list of URLs pointing to the representative image file(s). Images must be at least 160×90 pixels and at most 1920×1080 pixels. We recommend images in .jpg, .png, or. gif formats. All image URLs should be crawlable and indexable. Otherwise, we will not be able to display them on the search results page.
Only marked-up images that directly belong to the article should be listed in this property. If there are multiple applicable images, please list them all with the important images first. |
| datePublished(required) | Date | The date and time the article was first published, in ISO 8601 format. |
| description | Text | A short description of the article. |
| articleBody | Text | The actual body of the article. |
| alternativeHeadline | Text | A secondary headline for the article. |
Het nieuwssnippet op de zoekresultatenpagina ziet er als volgt uit:
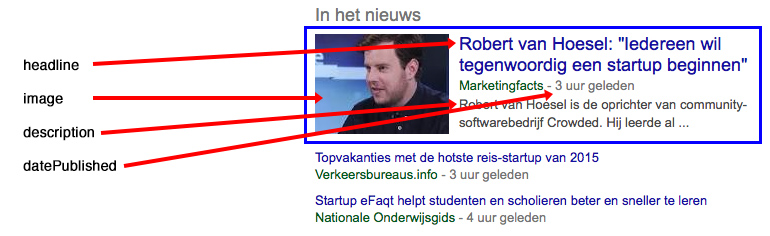
Een content carousel ben ik in de Nederlandse zoekresultaten nog niet tegenkomen. Maar deze ziet er als volgt uit. Je ziet hierin dezelfde informatie terugkomen als het ‘nieuws’-snippet.
De creative commons declaratie voor afbeeldingen, die we in artikelen hebben opgenomen, wordt actief gebruikt voor Google Image Search. Binnen het zoeken naar afbeeldingen kun je namelijk zoeken op rechten van afbeeldingen. Middels de creative commons declaratie weet Google of de afbeelding rechtenvrij is, (commercieel) mag worden hergebruikt of auteursrechtelijk is beschermd. Het aanbod van afbeeldingen waarvan Google de rechten weet is op dit moment nog erg beperkt. Er zijn slechts een aantal websites die de rechten van de afbeeldingen vermelden. Zo vind je nu vooral resultaten van Flickr, Wikipedia en Pixabay.
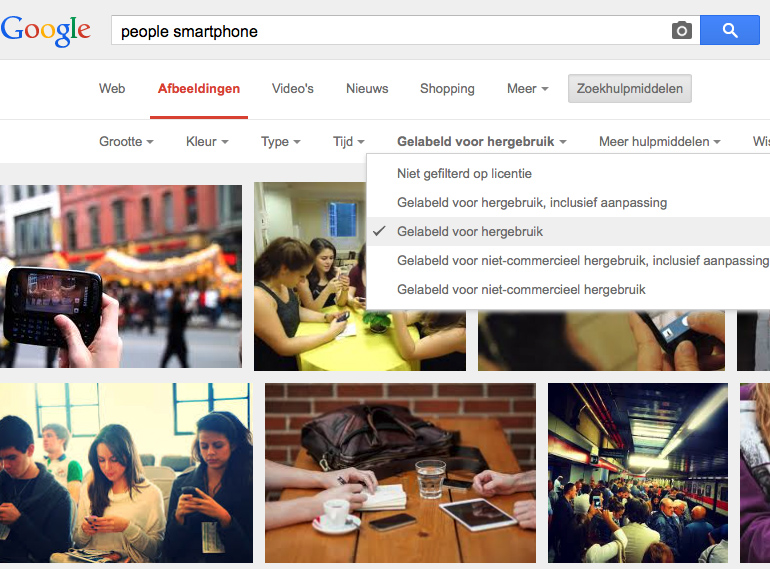
De uitdaging van het zoeken op afbeeldingen is dat er tekst moet zijn om beeld te omschrijven. Zo gebruikt Google de tekst van de webpagina om te bepalen waar de afbeelding over gaat. Op Wikipedia is er veel context, maar op afbeeldingenwebsites als Flickr ontbreekt die veelal. Extra context is daarom een welkome aanvulling. Zodoende merkte ik bij het zoeken naar nieuwe afbeeldingen dat bestaande afbeeldingen van artikelen op Marketingfacts erg hoog in de zoekresultaten stonden.
Het verkeer van Google Image Search is helaas niet makkelijk te onderscheiden van ‘normaal’ zoekverkeer van Google. Er bestaan wel enkele trucs om dit wel te kunnen meten, maar deze heb ik (nog) niet geïmplementeerd op Marketingfacts. Het exacte effect op aantallen bezoeken kan ik daarom helaas niet benoemen.
Foutje!
Er is enkele maanden terug helaas een fout geslopen in onze creative commons declaratie waardoor afbeeldingen van marketingfacts.nl niet meer in de zoekresultaten voor creative commons afbeeldingen terug te vinden zijn. De fout is op dit moment verholpen maar de afbeeldingen zie ik nog niet in grote getalen terugkomen.
Een fout als deze is typerend voor fouten binnen elementen die voor gebruikers niet te zien zijn. Zulke fouten kunnen er vrij ongemerkt insluipen en zoals nu het geval was, was de schade al groot op het moment dat ik ontdekte.
Afsluitend
Personen en reacties worden op dit moment nog niet door Google gebruikt voor ‘richt snippets’. Net als voor meta-informatie geldt voor schema.org-gegevensopmaak dat het belangrijkste doel het optimaliseren van de click-through rate, het percentage bezoekers dat doorklikt op jouw webpagina in de zoekresultatenpagina, is.
Nog niet alle onderdelen van schema.org worden door zoekmachines gebruikt, maar het gebruik ervan is wel groeiende. Daarom is het slim om, als je dan toch aan de slag gaat met een deel van de elementen, je net zo goed meteen een hele hoop kunt implementeren. Wie weet pakt Google volgende week dat volgende element wel op en ben je de concurrentie meteen voor.
Belangrijk nog om te vermelden is dat het opnemen van gegevensopmaak geen garantie is dat Google deze informatie ook daadwerkelijk toont. Google toont deze informatie alleen als het meent dat het relevant is (daarom kan het resultaat per zoekopdracht verschillen) en als de authoriteit van de website hoog genoeg is.
Ik wil Eduard Blacquière, Remi van Beekum, Martijn Hoving en Jordy Noll bedanken voor het sparren en de zeer waardevolle feedback op dit artikel. In het volgende artikel ga ik dieper in op linkwaarde.

Data-gedreven digital marketeer. Resident bij Amdax en Woonduurzaam. Daarnaast vertel ik vaak als spreker over data-gedreven marketing. Auteur van het boek Data-bedreven marketing. Eén van de twee Groene Nerds.
Een compleet en waardevol artikel voor website ontwikkelaars en online marketeers.
Zelfs als een website nog niet de autoriteit heeft om door Google als waardevol gezien te worden om alle rich snippets te tonen, is het van belang om ze te hebben.
Zeer behulpzame info, dank je wel!
Bij het uitproberen in de Markup Helper wordt ook URL als tag mogelijk gesteld. Ik hoop dat het niet de bedoeling is om al je URL’s op de pagina te taggen.
Daarnaast heb ik nog de vraag of je de tags op elke pagina moet plaatsen. bijvoorbeeld wanneer je klantbeoordeling van je bedrijf telkens in de body terug komt, is één keer taggen dan genoeg of moet dit op elke pagina gebeuren?
Hi Joran,
In je reactie heb je het over de terugkerende taak van taggen. Ik zie het meer als het element taggen. Wanneer dat element op meerdere pagina’s terugkomt, dan heeft het ook die tags. De tags horen dan dus gewoon bij het element, het vertelt immers ‘hey Google, in dit element vind je altijd informatie over reviews, waar ik ook sta’.
Zeer interessante informatie. Hier ga ik eens heel goed naar kijken.
Hartelijk dank!
Interessant artikel. Echter volgens mij een klein foutje:
“een initiatief van de drie grote zoekmachines Yahoo!, Bing, Yandex en Google.”
Je spreekt over ‘de drie grote zoekmachines’ en noemt er 4?
Daarbij rich snippets zorgen volgens mij inderdaad voor een hogere CTR. Nu kan ik mij vergissen, maar was het niet ook altijd zo dat een hogere CTR op termijn ook je positie verbetert? De gebruiker geeft daarmee immers als het ware impliciet aan jou een nuttig resultaat te vinden. Ik heb altijd begrepen, dat Google dit ook mee laat wegen.
Heel interessant! Schema.org snippets worden meestal overgeslagen.
P.S. Een klein schrijffoutje – Dit doet ‘Goole’ bijvoorbeeld met autocomplete
Goede verwoording, Danny: ‘Het gaat niet om wat je expliciet intypt, maar om wat je impliciet bedoelt.’ Op basis van eigen ervaringen hierover: wat goed werkt, is het vooraf opschrijven van de belangrijkste vragen die een zoeker kan hebben bij je product of dienst. Op die manier ga je denken als een zoeker, in veel gevallen jouw (potentiële) klant. Door vervolgens antwoord te geven op deze vragen met de content, en daarbij ook soms letterlijk een vraag terug te laten komen als h2 of in de tekst, maak je niet alleen de bezoeker, maar ook Google erg blij met relevante content.
Yahoo en Bing maken tegenwoordig gebruik van hetzelfde algoritme en kunnen in dat opzicht als één worden beschouwd.
where to buy ventolin inhaler
cialis price cvs pharmacy
where to buy viagra without prescription
order viagra online without prescription
best place to buy generic viagra
viagra for men how does it work
best place to buy generic cialis
cialis daily use dosage
lowest price generic cialis
where to buy cheap cialis
viagra tablets 100mg x 4
buy viagra cheap
buy viagra online canada
buy misoprostol in australia
viagra fast delivery
Gerelateerde artikelen
Marketingfacts. Elke dag vers. Mis niks!
Marketingfacts. Elke dag vers. Mis niks!