Problemen Amazon Web Services legt deel Web 2.0 plat

Amazon.com biedt al geruime tijd, naast de webwinkel, een serie webdiensten aan zoals het hosten van bestanden (S3), het uitbesteden van serverkracht op afstand (EC2) en het draaien van databases (SimpleDB). Daarmee kunnen bedrijven snel en betaalbaar een schaalbare architectuur bouwen voor hun webapplicaties. Er kleeft echter wel een ‘klein nadeeltje’ aan. Als er problemen met Amazon Web Services zijn, dan ligt een groot deel van de nieuwe webapplicaties zoals Audible, Plurk, Slideshare, Twitter en Vimeo ook op zijn gat!
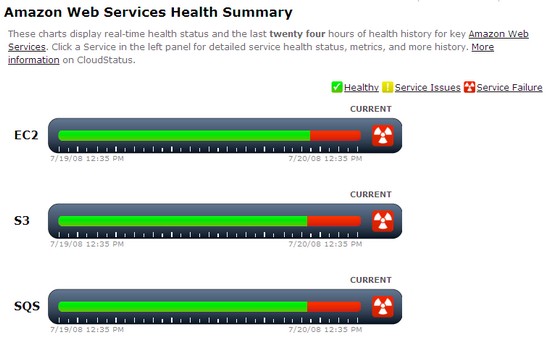
Via Cloudstatus.com (met dank aan Loes) zien we dat de problemen vanmorgen vroeg al zijn begonnen maar pas eind van de middag voor grote problemen zorgden (waarschijnlijk omdat op dat moment ook de internetgebruikers in de VS online gingen). Via Twitter is aardig inzicht te krijgen tegen welke problemen de internetgebruikers aan lopen.
Oprichter/partner Upstream, Marketingfacts, Arnhem Direct, SportNext, TravelNext, RvT VPRO, Bestuur Luxor Live, social business, onderwijs, fotografie en vader!
Ik heb sinds een maand of 3 maand al mij image files (een paar gigabyte) ondergebracht bij Amazon S3. Dit is de eerste grote storing die ik meemaak. Op zich natuurlijk wel vervelend. Maar daar tegenover staat dat de Amazon Web Services wel enorm veel mogelijkheden biedt tegen zeer lage kosten….Het is bijna gratis…
Het is wel vreemd dat ze geen failover hebben … maar dat zal in de toekomst ook wel beter geregeld worden…
Ze hebben inmiddel een oplossing gevonden en zijn momenteel bezig om de servers weer in de lucht te brengen…
@Jos: heb jij als gebruiker van deze services nu ook een bericht van ze ontvangen wat nu precies het probleem is en hoe lang ze denken nodig te hebben om de problemen op te lossen?
Wat mij vooral intrigeerde is het feit dat veel, heel veel Web 2.0-applicaties gebruik maken van de Web Services van Amazon. Eén probleem bij Amazon en een deel van Web 2.0 ligt dus helemaal op zijn gat.
herstel, S3 UK is ook om.
@Wilbert: yep, we krijgen zo een mooi overzicht; dat dan weer wel 😉
@Eelco: zit het net te lezen! Wat is de relatie van Hyperic eigenlijk met Amazon Web Services?
@Marco Ik had tot dusverre nog nooit problemen gehad en zag dus niet de noodzaak om mij te abonneren op hun feed. Ik heb binnen een paar minuten wel hun statuspagina gevonden waarin om het half uur een update word gedaan van de voortgang…
Het probleem zit hem in de Simple Storage Service (S3). Zowel de S3 Service in de US als in Europa ging gelijktijdig down. Ik vermoed door de inzet van ee nieuwe software versie. Wat mij betreft testen ze dat voortaan eerst uit in de US…
Ik vermoed dat veel Web 2.0-applicaties vanuit kostenoverwegingen niet zonder Cloud Computing kunnen…Heel simpel… Men kan onbeperkt schalen en het kost echt nagenoeg niets…
@Kjeld Zit het probleem niet in het bepalen van wat wel/niet longtail content is ? En dat moet je zelf ook weer allemaal gaan bijhouden… Ik geef er zelf de voorkeur aan om alles gewoon bij hun neer te zetten en incidenten op de koop toe te nemen…Dat kan ik mij overigens ook veroorloven
@Jos Long tai bepalen doe automatisch opbasis van request/buffering simpel algaritmetje.
In het laatste zit de kern, als je Twitter bent en hebt 30 miljoen funding gehad dan kun je j dat niet verooloven in mijn ogen, ik vindt het amateuristic. Als hijves images down zouden zijn zou ik het niet vinden kunnen.
Vraag is: Kun je het zelf beter dan Amazon? aAs je eigen server(s) uitvallen heb je het zelfde probleem wat je bovendien zelf moet oplossen. Nu hoef je alleen maar naar Amazon te wijzen…
@andere Niek:
“Kun je het zelf beter dan Amazon?”
Dat zeg je op de basisschool of desnoods nog op de middelbare school. Hier mag je gewoon er over praten als iets niet werkt waarvoor je betaalt, of dat nou veel of weinig is. Ik had eerst “klagen” i.p.v. “praten” geschreven maar zelfs dat is het niet. Het artikel heeft gewoon een informerende toonzetting en is in mijn optiek geen beschuldigend vingertje richting Amazon.
@Niek ten Hoopen
Ik reageerde op het “verwijt” aan Twitter door Kjeld. Immers, ook met 30 miljoen in de pocket is het niet te voorkomen dat er af en toe storingen in de infrastructuur optreden. Maar Twitter kan zich beter concentreren op het stabiel maken van haar software. i.p.v. geld en tijd te steken in infrastructuur. En natuurlijk mag je/moet je praten over storingen om Amazon bij de les te houden. De hoeveelheid kennis/ervaring bij Amazon is echter door bijna geen enkel bedrijf te evenaren. Wellicht dat Google met haar nieuw App Engine service in de buurt gaat komen. Het levert in ieder geval concurrentie op voor Amazon wat de kwaliteit van de dienstverlening alleen maar ten goede kan komen.
Wat mij verbaast is het feit dat er geen enkele wijze van backup is. Wat betekend dat de hele wereld van 1 plaats zijn gegevens tabt. De googles van deze wereld hebben toch echter overal data storages enzo, waarom dan het uitvallen van 1 verdeelpunt fataal voor deze diensten?
Gerelateerde artikelen
Marketingfacts. Elke dag vers. Mis niks!
Marketingfacts. Elke dag vers. Mis niks!