10 technische SEO-takeaways

De belangrijkste technische inzichten vanaf het BrightonSEO-congres
Op vrijdag 22 april vond een van de grootste SEO-congressen van Groot-Brittannië plaats in Brighton. De Brighton Dome in het centrum van de stad bood een prachtig decor voor alweer het zesde achtereenvolgende jaar dat het SEO-congres georganiseerd werd. Samen met mijn collega heb ik het congres bezocht en hier zijn een aantal interessante punten naar voren gekomen voor het verbeteren van de techniek van een website. Het verbeteren van de techniek van een website wordt vaak ondergewaardeerd. Graag deel ik onderstaande tien technische takeaways van BrightonSEO!
#1: Crawl-optimalisatie
Crawl-optimalisatie houdt in dat de spiders van de zoekmachines zo min mogelijk tijd spenderen aan het crawlen van de juiste URL’s op de website. Waarom is dit belangrijk? Omdat elke website is gebonden aan een crawlbudget. Je wil niet dat het crawlbudget wordt verspild aan minder belangrijke URL’s (crawl waste). Het is wenselijk dat de meest relevante en belangrijke pagina’s binnen een website regelmatig worden gecrawld.
Volgens Dawn Anderson hebben crawlers een crawlingschema. Dit schema bestaat uit drie rangen:
- Real time crawling: de URL’s die zijn ingedeeld in deze rang worden meerdere keren per dag bezocht door de crawlers van de zoekmachines
- Dagelijks crawls: in deze rang worden de URL’s elke dag óf om de dag gecrawld
- Basis crawls: alle URL’s die hieronder vallen worden onderverdeeld in verschillende segmenten. Deze segmenten worden vervolgens om de beurt gecrawld. Hier wordt de lijst per segment afgewerkt, wanneer het einde is bereikt begint het crawlen pas weer opnieuw.
Het verschilt per website welke URL’s onder welke rank in het schema vallen. Zo kunnen de belangrijkste URL’s van een website onder de eerste of tweede rang vallen, maar de minder belangrijke URL’s onder rang drie. Anderson vertelde ook dat als er een nieuwe URL wordt gevonden de crawler niet direct de nieuwe pagina crawlt, maar eerst in een rang indeelt en daarna pas terugkomt.
#2: Optimaliseer XML-sitemaps
Om ervoor te zorgen dat de crawlers zo min mogelijk tijd kwijt zijn aan het crawlen van de verkeerde pagina’s is het optimaliseren van de XML-sitemap een goede zet. Zorg dat de XML-sitemap alleen URL’s bevat die ‘final’ zijn. Minimaliseer 301-redirects en andere statuscodes die niet 200 zijn. Test bij welke URL’s er veel crawl waste aanwezig is. Dit kan door middel van het aanmaken van meerdere sitemaps en deze toe te voegen aan Google Search Console. In GSC kan je zien hoeveel pagina’s er zijn gecrawld en hoeveel er zijn geïndexeerd.
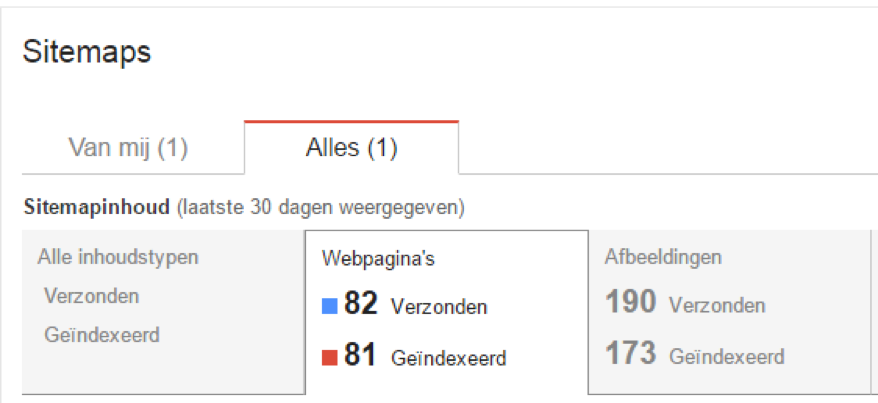
Zit hier een groot verschil tussen? Zie je hier 20.000 verzonden en 11.000 geïndexeerd? Dan is het belangrijk om verder onderzoek te doen naar welke pagina’s voor zoveel waste zorgen. Als blijkt dat er te weinig URL’s worden geïndexeerd, controleer dan de statuscodes van alle pagina’s. Het kan voorkomen dat er teveel 301-redirects of te veel kapotte pagina’s (404 statuscode) zijn. Een handige tool die wij hiervoor gebruiken is Screaming Frog. Hiermee kan je snel en eenvoudig in een overzicht alle statuscodes van de website bekijken.
#3: GoogleBot
Het liefst wil je dat pagina’s binnen je website regelmatig worden gecrawld, zodat Google aanpassingen aan de website sneller oppikt en indexeert in de zoekmachine. Het creëren van nieuwe, unieke en goede content is daarom een must.
Vermijd geautomatiseerde content en schrijf elke pagina uniek. Voor webshops is dit vaak een arbeidsintensieve klus. Veel webshops gebruiken de standaard informatie van leveranciers op de website. Hierdoor zijn de teksten niet uniek. Er zijn aanwijzingen dat pagina’s met geautomatiseerde content minder frequent worden gecrawld door GoogleBot. In exterme gevallen kan het zijn dat GoogleBot besluit om de pagina helemaal niet meer te crawlen. Schrijf altijd unieke content!
#4: Optimaliseer gepagineerde content
Neem als voorbeeld een webshop die voetbalschoenen verkoopt. In totaal verkoopt deze webshop tachtig schoenen van merk X in één categorie. Deze tachtig voetbalschoenen heeft de webshop onderverdeeld in veertig voetbalschoenen op de eerste pagina en veertig voetbalschoenen op de tweede pagina. Dit wordt ook wel gepagineerde content genoemd.

Bij gepagineerde content ontstaat er vaak crawl waste, omdat er veel pagina’s worden gecreëerd die de crawler moet bezoeken. Barry Adams gaf tijdens zijn presentatie de volgende tips om crawl waste bij gepagineerde content tegen te gaan:
- Toon meer producten op één pagina
- Gebruik de rel=”next” & rel=”prev” tag in plaats van een canonical tag
- Blokkeer de sorteer parameters, zoals het sorteren van de prijs, in het robots.txt bestand
#5: Check Google Search Console regelmatig
Controleer regelmatig de berichten en gegevens in Google Search Console. Als je een bericht ontvangt met de boodschap dat er een groot aantal URL’s gevonden zijn dan weet je zeker dat het crawl budget niet optimaal wordt benut en dat er onnodige URL’s worden gecrawld.
Naast de berichten zijn de data bij Google-index en Crawlen ook erg belangrijk (en interessant) om regelmatig te monitoren.
#6: Optimaliseer gefilterde pagina’s (faceted navigation)
Websites met filters, bijvoorbeeld het filteren op merknaam/thema/kleur, vergeten vaak om deze te optimaliseren voor de crawlers. Bepaal welke filters een toegevoegde waarde hebben voor de bezoeker en maak hier een statische pagina van.
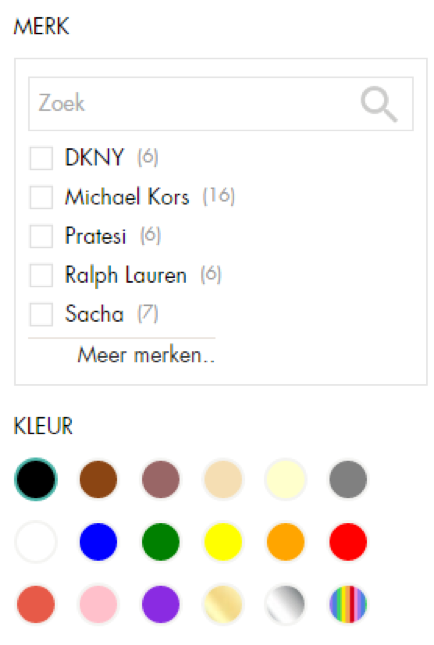
Stel een webshop verkoopt tassen. Een subcategorie is leren tassen. Bij deze subcategorie is het mogelijk om te filteren op een zwarte kleur. Maak voor deze filtermogelijkheid een statische pagina en optimaliseer deze pagina aan de hand van de onpage-factoren. Deze pagina zal vervolgens beter gaan ranken voor de term zwarte leren tas.
De filters die geen toevoegde waarde hebben kan je het beste blokkeren in het robots.txt bestand. Een andere optie is om een rel=”nofollow”-tag toe te voegen aan de filters. Op deze manier wordt het crawl budget optimaal benut.
#7: Blokkeer indexatie van interne zoekopdrachten
Tijdens het congres werd het probleem van indexatie van de interne zoekopdrachten ook besproken. Zelf komen we dit in de praktijk ook vaak tegen. Vaak hanteren websites een interne zoekmachine (zoekbalk) op de website. Mocht je hier gebruik van maken, let dan wel op dat je de interne zoekopdrachten niet laat indexeren. Doe je dit niet dan wordt er voor elke interne zoekopdracht een nieuwe URL aangemaakt en creëer je onnodig URL’s. Je kan de zoekopdrachten uit de interne zoekmachine blokkeren in het robots.txt bestand. Het verschilt per website hoe de URL eruitziet. Hieronder volgen een paar voorbeelden:
User-agent: *
Disallow: /searchresults.aspx
Disallow: /*query=*
Disallow: /*s=*
#8: Migratie van HTTP naar HTTPS
Veel websites migreren vandaag de dag van een http-website naar een https-website. Bij zo’n grote migratie komt veel kijken. Er zijn veel belangrijke punten die je moet doorlopen om ervoor te zorgen dat een migratie soepel verloopt. Eén van die punten is ervoor zorgen dat de nieuwe https-website zo snel mogelijk wordt geïndexeerd door Google. Voeg een nieuwe sitemap toe aan Google Search Console. Laat tegelijkertijd ook de oude sitemap staan en zorg dat alle 301-redirects goed zijn ingesteld. Als de crawlers deze sitemap bezoeken, dan worden ze direct doorgestuurd naar de nieuwe website.
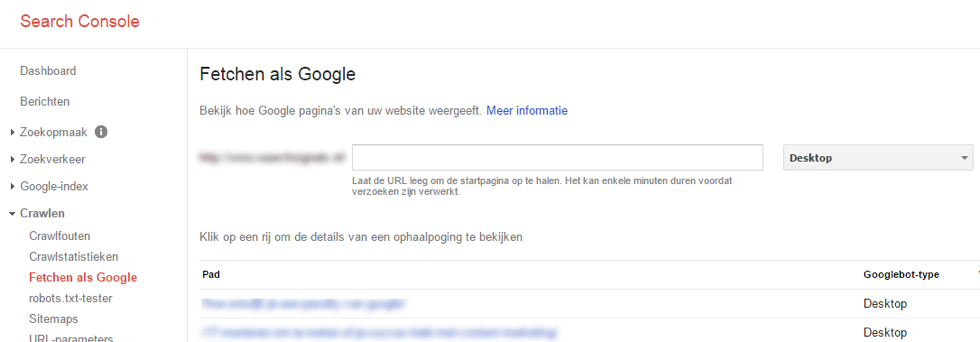
In Google Search Console is het ook mogelijk om de nieuwe HTTPS URL’s te fetchen als Google. Gebruik de belangrijkste URL’s van de website en haal deze op met behulp van deze tool. Dit geeft een extra stimulans aan een snelle indexatie van de nieuwe pagina’s.
#9: Juiste implementatie van de canonical tag
Barry Adams benadrukte het gebruik van de canonical tag op de juiste manier. Gebruik de canonical tag voor indexeringsproblemen en niet voor crawlproblemen. Crawlers moeten deze tag namelijk eerste zelf ‘zien’ voordat ze ernaar handelen. Oftewel pagina’s moeten eerst gecrawld worden voordat de rel=”canonical”-tag effect heeft.
Hetzelfde geldt voor NoIndex-tags. Gebruik canonical-tags niet voor gepagineerde content, pagina’s met filters of het blokkeren van pagina’s met interne zoekopdrachten. Gebruik de canonical-tag wel voor het volgende:
✓ Als er aparte websitepagina’s zijn voor de mobiele website
✓ Voor URL’s waar parameters in voorkomen waarin sessie specifieke informatie staat
✓ Duplicate content
#10: Snelheid van de website
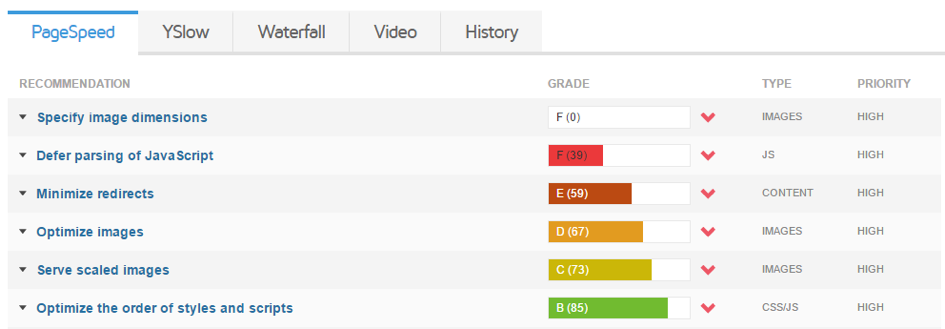
Naast deze technische punten werd tijdens BrightonSEO ook veelvuldig de toegevoegde waarde van een snelle website benoemd. Gebruik voor het testen van de snelheid niet alleen Google Pagespeed Insights maar ook andere bronnen, zoals Webpagetest.org of GTmetrix. Ook hier is het een goede zet om regelmatig de prestaties van de individuele pagina’s te monitoren, bijvoorbeeld de top tien bestemmingspagina’s.
Het merendeel van bovenstaande punten zijn eenvoudig om op te lossen. Maak jij al gebruik van bovenstaande technische punten? Of heb je tips die hier niet staan beschreven? Laat het weten in een reactie!
Reinier Bus is online marketeer bij Search Signals. Search Signals helpt bedrijven bij het bereiken van de doelgroep in iedere fase van de customer journey. Reinier houdt zich bezig met de dynamische wereld van zoekmachine marketing waarbij nieuwe ontwikkelingen niet lang op zich laten wachten.
2 Reacties
Plaats reactie
Je moet ingelogd zijn op om een reactie te plaatsen.
@Ralf van Veen, toen het artikel geschreven was was dit nog wel het geval 🙂
Grappig om te zien dat iedereen zich altijd focussed op de kleine veranderingen die Google jaarlijks maakt, terwijl 90% van de sites de basis niet op orde hebben.