De creatief toch overbodig? Watson’s Lexus-commercial onder de loep

‘s Werelds eerste door AI ontwikkelde commercial getest op effectiviteit
Commerciële creativiteit was ooit het exclusieve domein van de reclamemakers. Een vak apart. Daar werd je mee geboren. Dat kon verder niemand. Geen accountmensen en al helemaal geen klant. Dus toen ik twee jaar geleden verkondigde dat het niet lang meer zou duren voordat Artificial Intelligence zich met ons vak zou gaan bemoeien en creatie op veel terreinen zou kunnen vervangen, werd ik uitgelachen en voor gek verklaard. Maar nu is daar de Lexus-commercial, gemaakt door AI-computer Watson. Worden creatieven dan toch overbodig?
Een paar weken geleden las ik dat Watson, de AI-computer van IBM, een tv-commerial voor Lexus had gemaakt. En dan niet de uitwerking of filmshopping waarvoor computers al een jaar of twintig gebruikt worden, nee, de AI had het script geschreven. Niet zomaar een script, want en passant was ook de lengte van de shots en de overgang aangegeven. Grappig genoeg heeft ze het ook zelf voorgelezen, zoals een tekstschrijver dat zou doen. Ja, je leest het goed: ‘ze’. De jongens en meisjes van IBM hebben Watson een vrouwenstem meegegeven. Als een waarschuwing voor alle overwegend mannelijke creatieven in ons vak? Of was het als tegenwicht bedoeld voor het productieteam dat de commercial moest maken, vijf mannen en één vrouw?
Watson’s commercial
Watson is een vergaarbak van algoritmes die weer door andere algoritmes worden gemanaged. Algoritmes moeten getraind worden, deep learning. Dat heeft men ook met Watson gedaan, ze hebben haar geleerd wat goede reclame is, door haar vijftien jaargangen van internationale ‘awardwinnende’ reclames te laten zien. Daaruit leerde ze wat de interactie is tussen de mens en zijn auto. Ze leerde emoties te begrijpen en aan de hand van neurostudies werden de algoritmes getraind om deze te categoriseren. Ook werd ze gevoed met woorden en zinnen die deze emoties en gevoelens representeren, en hoe deze emoties leiden tot een beslissing. Vervolgens werd ze gebriefd. Tja.., een ‘creatief’ gaat natuurlijk niet zonder briefing aan de slag. Het moest een commercial worden die het intuïtieve karakter van de auto, de nieuwe Lexus, uit de doeken deed.
“Watson leerde wat de interactie is tussen de mens en zijn auto”
Enkele minuten later was Watson klaar. Er werd een productieteam samengesteld uit de besten in hun discipline. Een tekstschrijver, een producer en natuurlijk een regisseur. Tezamen met de klant kregen ze het script gepresenteerd. In de making of hoor je Watson met overtuiging het script uitleggen.
Ze wil meteen de auto groots in beeld, omgeven door een bijzondere verlichting. Dan zien we een lange trip naar een ontmoetingsplaats die op voorhand al onheilspellend wordt gemaakt doordat de auto richting onweer-suggererende donkere luchten rijdt. Uiteindelijk blijkt de plaats van het rendez-vous een crash-test-site te zijn, waar de Lexus tegen een vrachtwagen zal crashen. Alleen…, dat gebeurt niet. Het automatische remsysteem van de Lexus grijpt in en wint het van de trekkracht van de op de vrachtwagen gemonteerde winch. Dit alles tot opluchting van de ontwerper van de auto die de verrichtingen van zijn ‘geesteskind’ via een beeldscherm volgt, samen met zijn vrouw. Packshot, logo, muziekje.
Prachtig, maar ook effectief?
Zowel de tekstschrijver als de klant zeggen angst te hebben gevoeld, toen ze ervoor kozen om alles precies zo te maken als Watson heeft ‘gedicteerd’. Eerlijk is eerlijk, het is een prachtige commercial geworden. De vraag is natuurlijk, is-ie ook goed? Doet-ie wat het moet doen, namelijk mensen aanzetten tot de aankoop van deze nieuwe Lexus, of op zijn minst de aankoop ervan in overweging nemen? Het leek ons een geweldig idee de werking van deze AI-gecreëerde commercial met MRI te bestuderen. Kan Artificial Intelligence de (onbewuste) emoties van een mens nét zo beroeren als topcreatieven dat kunnen?
“Kan AI de emoties van een mens nét zo beroeren als topcreatieven dat kunnen?”
Om dat goed te beoordelen, doen wij eigenlijk hetzelfde als IBM, maar dan andersom. Wij laten consumenten de commercial zien, terwijl ze in een MRI-scanner liggen. Zo onttrekken we neurale activatie uit het brein die door de beelden is opgewekt. Dit vergelijken we met de hersenactivatie waarmee onze algoritmen getraind zijn, namelijk met die van meer dan honderdveertig commercials. Niet alleen de winnaars van creatieve prijzen als Gouden Loeki’s, maar ook met Effies en – als tegenwicht – Loden Leeuwen.
Een Gouden Loeki
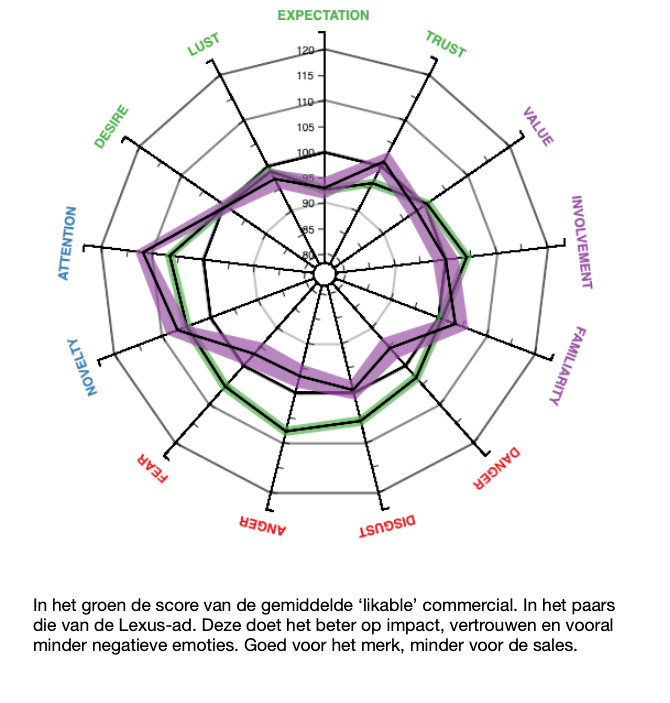
In onze studie scoort de Lexus-commercial vooral erg goed op ‘likability’, zeg maar de gemiddelde Gouden Loeki. En dat verbaast ons eigenlijk niets. Wie het gemiddelde effect van tientallen prijswinnende commercials in één uiting kan vangen, kan er bijna niet naast zitten. De spider-grafiek laat zien waar dat vandaan komt. Veel aandacht en verrassing, en goed van vertrouwen, maar vooral weinig negatieve emoties. Maar ja.., de correlatie met effectiviteit is negatief, of beter gezegd: hij doet niet bijzonder veel voor de verkoop van de auto. En dat is uiteindelijk waar reclame voor bedoeld is.
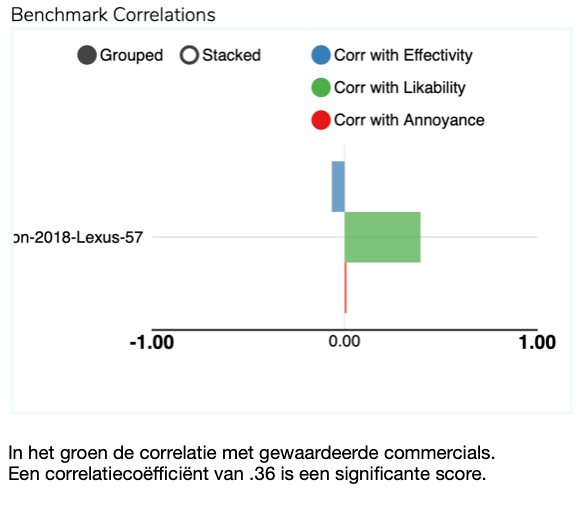
Zit Watson er dan toch naast? Is AI nog niet in staat om een commercial te ontwikkelen die de verkoop dient? Ik denk het wel, het probleem is echter de input. AI kan alleen maar leren van dat wat is aangereikt. In dit geval dus vijftien jaargangen prijswinnende commercials. En daar zit ‘m nou nét de kneep.
Reclame- en marketingmensen geven elkaar prijzen voor opvallende, leuke, mooie en bijzondere reclame. Alle commercials die ze Watson hebben gevoed, zijn precies van dat soort. Ze hadden natuurlijk ook commercials moeten laten zien die misschien niet mooi of grappig zijn, maar wel goed verkopen, bijvoorbeeld zo’n zeventig Nederlandse, Amerikaanse en Duitse Effies.
In de wetenschap dat het brein niet liegt en wij op wetenschappelijke wijze correlaties kunnen meten tussen verschillende neurale patronen, moeten we concluderen dat Watson scheppend vermogen heeft laten zien. Watson was creatief. Er was een briefing en even later een script dat voldeed aan de briefing.
“Watson kan zelfs een Gouden Loeki-waardige creatie maken”
De letterlijke uitvoering ervan is in staat gebleken de concurrentie aan te kunnen met commercials die wij mensen waarderen. Watson is zelfs zó creatief dat ze een Gouden Loeki kan maken. En er zijn niet veel creatieven die dát kunnen zeggen. Goed.., het is nog geen commercial (laat staan een campagne) die de koopintentie activeert, maar dat is dus een kwestie van het trainen van de algoritmen met de juiste informatie.
Algoritmen leren algoritmen
Ook bij het trainen van de algoritmen met de juiste informatie komen straks geen mensen meer aan te pas. Met de recent verkregen bankstatus van Google wordt voor het eerst in de geschiedenis zoekgedrag gekoppeld aan koopgedrag! Algoritmen laten dan zien welke commercials tot de hoogste verkoop hebben geleid, en de kennis die Watson al heeft, laat dan vooral zien welke neurale structuur daarvoor verantwoordelijk is. Zo maken de Watsons straks commercials die én leuk zijn, én goed verkopen. Wij mensen mogen ze dan in elkaar zetten. Voor wie mij niet gelooft, verwijs ik graag naar een studie van Google Brain, waarin twee AI’s een geheimtaal hebben ontwikkeld die door een derde AI gevoed met exact dezelfde kennis als beide anderen, niet gekraakt kon worden. Als dat niet creatief is?
“AI maakt straks commercials die én leuk zijn, én goed verkopen”
Reders van zeilschepen hebben gelachen om de eerste stoomboot. Hoefsmeden wuifden schuddebuikend naar de eerste auto’s die alleen de weg op mochten voorafgegaan door een man met een rode vlag. De gebroeders Wright waren de risee van het dorp en boden meer vermaak dan het plaatselijke theater. De Duitse auto-industrie heeft wat meewarig naar de inspanningen van Tesla gekeken. NASA tekende vorige maand een contract met een commerciële ruimtevaarder voor bemande vluchten. Maar gelukkig is creativiteit voorbehouden aan creatieven. Dat kunnen managers en klanten niet. En al helemaal geen computers, toch?

Neuromarketing Consultant, studied the effect of 2,800 stimuli in 55,000 fMRI-scans. One of the most experienced neuromarketing experts in the world. Commercial partner and co-founder of Neurensics. Co-founder and name giver of the NMSBA. Frequently asked for expert opinion and lectures at conferences. Author of ' De Koopknop' and publisher of numerous neuromarketing studies.
1. Het verbaast me niet dat Martin van Neurensics fan is van de methode van Martin van Neurensics. Het verbaast me wel dat MF zo’n advertorial plaatst (niet voor het eerst).
2. Martin mist het doel van deze campagne compleet. Het doel is niet het produceren van een TV commercial, maar gratis PR behalen door het inzetten van AI en zo Lexus aan innovatie te koppelen. Als Watson zelf zo slim was om deze inzet te verzinnen, dan zou ik me druk gaan maken over mijn bestaansrecht als creatief.
3. Vroeg of laat zal AI wel zo slim zijn, maar tegen die tijd zijn we zo goed als allemaal overbodig.
Een meting is een meting en geen mening. En een correlatie is een correlatie; statistiek. Geen onderzoeker die daaraan twijfelt. Dus scoort deze commercial beter dan die van de gemiddelde creatief, zo simpel is het. En hij is gemaakt door een computer. Of denk jij nou echt Coerd zonder achternaam, dat dit alles doorgestoken kaart is? Dat IBM zich leent voor het produceren van een hoax? Dat Watson een of ander Mickey Mouse programmaatje is? Lees dan nog even het artikel in The Guardian van Stephen Hawkins over AI: later komst steeds sneller.
Coert. (Sorry voor de d). Dat jij onze methodiek pseudo-wetenschappelijk noemt, zullen mijn partners professor Lamme en as. professor Scholte je niet in dank afnemen, en ik nodig je dan ook van harte uit om hier op de UvA deze discussie eens met hen te voeren. Wij vergelijken het neurale netwerk van deze commercial, gemeten onder een representatieve steekproef, met het gemiddelde neurale netwerk van 70 effies, 60 Gouden Loekies en ongeveer evenzovele Loden Leeuwen. Dit hebben we gemeten met inmiddels enkele duizenden hersenscans. Daar valt niets aan te interpreteren: deze tvc correleert significant met een Gouden Loekie (publieksstemming). “Als Watson zelf zo slim…..als creatief”. Hier lees ik toch echt dat jij zegt dat Watson niet ‘slim’ genoeg is om een tvc-script te schrijven. En jij hebt gelijk dat Watson (nog) niet weet wat goed of slecht is. Sterker.., dat toont onze meting aan, want deze commercial is eerder opvallend en interessant dan dat-ie goed is voor de verkoop (geen Effie-correlatie). Ik ben het ook met je eens dat niet “alle chefs ineens overbodig zijn” maar heeeeel veel koks straks wel. Dat ‘straks’ is dichterbij dan wij denken. De ontwikkeling van AI gaat sneller dan we misschien zouden willen, vooral nu algoritmen, algoritmen schrijven. Tot slot moet ik toegeven dat ik soms (te?) enthousiast ben over wat wij meten. Misschien mag ik daar als weerwoord op hebben dat wij honderden experimenten voor eigen rekening doen, enkel en alleen om te begrijpen hoe reclame werkt. Bij de publicatie ervan hebben we allemaal baat. En ik bied je hierbij aan om gratis en voor niets eens iets te testen dat jou inzicht en vertrouwen geeft in de meting die Lamme en Scholte hebben ontwikkeld.
“ik nodig je dan ook van harte uit om hier op de UvA deze discussie eens met hen te voeren”
Zou ik geweldig vinden, mocht ik in de buurt zijn, dan ben ik daar zeker voor in (mits de profs daar ook zvoor in zouden zijn).
“Hier lees ik toch echt dat jij zegt dat Watson niet ‘slim’ genoeg is om een tvc-script te schrijven.”
Nee, dat is niet wat ik zeg. Ik zeg dat er een gedachte achter het laten schrijven van een tvc-script door een AI zit, die dieper gaat dan het schrijven van een simpel tvc-script. Namelijk: door als eerste een door AI gescripte commercial te produceren creër je nieuwswaardigheid en dat resulteert in aandacht van de pers (bijvoorbeeld deze blog). Daarnaast koppelt het slim Lexus aan innovatie (show, don’t tell), compleet los van de inhoud van dat script.
Als Watson zo slim was geweest om met deze insteek te komen, was ik meer onder de indruk geweest en zou ik beginnen voor mijn baan te vrezen.
En het verbaast me dat die diepere laag je compleet lijkt te ontgaan.
“Dat ‘straks’ is dichterbij dan wij denken.”
Waarschijnlijk. Maar er zijn nog steeds erg grote hobbels te nemen. Dit proces is dermate complex dat elke voorspelling van onze kant niet meer is dan een natte vinger.
“En ik bied je hierbij aan om gratis en voor niets eens iets te testen dat jou inzicht en vertrouwen geeft in de meting die Lamme en Scholte hebben ontwikkeld.”
Dit vind ik een sympathiek gebaar en geeft aan dat je achter je product staat. Het meest overtuigend is als je iets vooraf kunt voorspellen. Dus ik zou graag horen welke commercial die jullie getest hebben, en die nog niet in roulatie is, enorm goed gaat verkopen?
Opmerking voor MF: Ik heb aangegeven reacties te willen ontvangen, maar ontvang niks.
“met het gemiddelde neurale netwerk van 70 effies, 60 Gouden Loekies en ongeveer evenzovele Loden Leeuwen”
Vraag aan jou of de Profs: Waarom is het gemiddelde neurale netwerk een nuttig uitgangspunt? Die 70 effies en 60 Gouden/Loden Loekies zijn effectief, sympathiek of vreselijk om heel verschillende redenen. Het gemiddelde daarvan (zelfs per subgroep) is (letterlijk) middelmatig.
Dat zie je ook bij het script van Watson. Het is heel erg middelmatig (wat voor een AI al een hele prestatie is) omdat het een soort gemiddeld script heeft gemaakt. Dus het is herkenbaar, maar het is creatief gezien niet goed (en ik deel je mening dat het weinig effectief is.)
Ik denk dat jullie methode een hoop zou kunnen verbeteren als je veel meer dan die 200 commercials erin zou stoppen en veel specifiekere neurale netwerken zou ontwikkelen voor verschillende genres commercials.
En toen bleef het opvallend stil…
Nee hoor, van science krijg je een snelcursus statistiek, zodat je zelf kunt uitrekenen waarom het gemiddelde altijd beter is dan de uitersten. Vandaar ook de gemiddelden van 3 verschillende groepen. Ik zou je graag van repliek dienen, ook op je eigen blog maar op een mobieltje aan de andere kant van de wereld is het ff lastig tikken. Maar ik kom bij he terug.
Leuk draadje!
Dag Coert, Andries van der Leij hier. Ik trek bij Neurensics de R&D kar.
Als eerste geef ik je gelijk dat het Droste effect in de reclame natuurlijk de echte reclame is. Je hebt de reclame en de making of. En op die making of duiken de kranten en de fora en de Tech community. En ook Neurensics en Marketing Facts en nu jij en ik. Allemaal zonder een cent inkoop en allemaal bekrachtigen we de associatie innovatie/tech <—> Lexus. Erg slim en dat moet Watson inderdaad nog maar eens verzinnen. Al heb je al een tijdje AI’s die AI’s bouwen, dus wie weet.
Neemt niet weg dat de casus an sich interessant is. Hoe goed brengt Watson het er van af? Dus leek het ons een leuke vorm van symmetrie hebben een creatief product van een AI te toetsen aan het brein. Immers: veel van de machine learning methoden die de huidige AI revolutie drijven, zoals Neurale Netwerken, zijn geïnspireerd op hoe leren op neuraal niveau werkt. Dus het is leuk om het weer eens om te draaien en een product ervan te toetsen tegen wet ware.
Nu je commentaar over het gemiddelde. Ik denk dat jullie het over verschillende dingen hebben. Een gemiddelde wordt steeds betrouwbaarder, maar is inderdaad niet perse goed als predictor omdat het de unieke features afvlakt. Als je maar genoeg data toevoegt aan wat dan ook regresseert alles naar het gemiddelde. Dat is ook niet alleen wat we doen. We kijken (altijd) met grote datasets naar een contrast: naar die kenmerken die Effies doen onderscheiden van reclames die geen prijs hebben gewonnen.
We hebben een zeer grote database met brein responsies op reclames. De breinresponsies die we meten met BOLD MRI vertalen we naar emoties met behulp van algoritmes die we hebben getraind op het daadwerkelijk beleven van die emoties: welk activatiepatroon voorspelt of je angst voelt? Onze benchmarking naar Effies doet eigenlijk hetzelfde, maar op een hoger niveau: welk patroon van emoties is voorspellend voor de klasse ‘Effie’ ten opzichte van controle reclames? We zeggen dus tegen onze machine: “hier heb je gegevens over hoe het brein op verschillende emoties reageert op reclames. Probeer jij eens met alleen die informatie te voorspellen of het een Effie is of niet.”
Dit lukt ons behoorlijk goed: we kunnen met machine learning Effies goed onderscheiden van niet-Effies door de machine alleen maar te voeden met de emoties als predictoren. Dat lukt een machine natuurlijk alleen maar als er gemeenschappelijks is dat Effies doet onderscheiden van niet-effies. Dus: er is een emotioneel patroon, ‘een recept’ zo je wil van Effies: gemiddeld gezien scoren Effies hoger op positieve emoties en lager op negatieve emoties dan niet-effies.
Hiermee heb je een benchmark te pakken: een statistisch patroon dat voorspellend is voor een externe variabele, zoals een prijs of sales. Dit is wat wij doen. We leggen een reclame langs een benchmark, dan krijg je een uitspraak over de kans dat de reclame emotioneel lijkt op bijvoorbeeld een Effie. Dan begint het werk pas, want die score zegt natuurlijk niets over waarom de reclame hoog of laag scoort. Daar hebben we weer andere tools voor.
Overigens krijg je een benchmark niet cadeau. Helaas zien we dat er flink gecowboyd wordt in het veld. Allereerst wordt het woord benchmark op verschillende manieren gebruikt. Wij noemen een score op een van onze emoties, zoals Fear, geen benchmark, omdat Fear niet iets representeert in de externe wereld, zoals loyaliteit, aankoopgedrag of bijvoorbeeld een prijs. Ten tweede is het veel, maar wel erg leuk werk. Je krijgt een benchmark niet door een studie te doen en net zolang aan knoppen te draaien tot je een sterke correlatie vindt. Je krijgt een benchmark door systematisch, keer op keer, in onafhankelijke, grote en representatieve steekproeven met grote hoeveelheden observaties een externe, betekenisvolle variabele goed te kunnen voorspellen.
Hallo Andries, bedankt voor je uitgebreide uitleg! Je verhaal klinkt al een stuk genuanceerder, maar het is van buitenaf lastig te beoordelen of deze methode nu wel of niet iets bruikbaars oplevert.
Ik ben dan ook benieuwd of jullie iets kunnen voorspellen wat meetbaar is?
Hoi Coert,
Jazeker! We doen niet anders. We hebben naast benchmarks voor Effies ook bijvoorbeeld benchmarks voor bijvoorbeeld pricing: patronen die voorspellen hoeveel geld mensen uit willen geven voor een product en ook een hele mooie voor (daadwerkelijke) donatiebereidheid. En we hebben samen met klanten een aantal benchmarks gebouwd en die zijn meestal gedekt met een NDA. Aangezien ik niet van accounts ben durf ik daar nooit wat over te zeggen. Maar ik denk dat je vraag is of onze voorspellingen wel eens uitkomen. Ook dat is waar. Hiervan is ook veel onder geheimhouding, maar we hebben een aantal heel mooie casussen. We hebben bijvoorbeeld op basis van breinresponsies succesvol voorspeld welke van 3 parallel uitgezette covers van hetzelfde issue van een glossy het beste zou verkopen.
Ja, ik bedoel idd dat laatste. Heb je een link naar de case?
Hoi Coert,
Dat kan Martin je beter vertellen. Ik zit meer aan de achterkant. Even geduld alsjeblieft.
Prima, ik wacht geduldig af.
In de tussentijd nog enkele inhoudelijke observaties ten opzichte van de input:
Jullie maken gebruik van Effies, Gouden Loeki’s en Loden Leeuwen.
Effies zijn vooral een prijs voor de strategie van een campagne (van de site: “Effie Award is een strategische prijs. Het gaat primair om de effectiviteit van de strategie die geleid heeft tot succes.”) Dat kan bijvoorbeeld een slimme inkoop van media geweest zijn. Het is dus gevaarlijk om de reactie op de inhoud van een Effie commercial te gelijk te stellen met effectiviteit. Misschien was het alleen uitermate effectief met de specifieke doelgroep van de campagne? Misschien werd er slim ingezet op een kortingsactie en had de inhoud van de commercial weinig met de reden van de effectiviteit te maken. Of was het product dat geïntroduceerd dermate goed dat het zich eigenlijk zelf wel verkocht. Daarnaast is er veel te manipuleren in de cijfers om een campagne meer efficiënt te laten lijken dan werkelijk het geval is. Hebben jullie rekening met dit soort zaken gehouden?
Gouden Loeki’s zijn voornamelijk reclames die het goed doen bij het grote publiek. Die hebben geen verstand van reclame en zullen in de regel het filmpje afrekenen op “vind ik dit een leuk filmpje?” De effectiviteit van deze commercials is redelijk onbekend, tenzij ze ook een Effie gewonnen hebben. Het is dus gevaarlijk om te beweren dat deze commercials alleen sympathiek zijn en niet efficiënt. Misschien zijn ze heel efficiënt geweest, alleen niet op een manier waarop je voor een Effie in aanmerking komt. Daarnaast geldt voor publieksprijzen dat er kuddegedrag meespeelt (zie ook de recente meest populaire Instagram foto: een ei) dat de uitslag danig kan vertekenen.
Als laatste de Loden Leeuwen. Dit is helemaal een rare categorie, want deze commercials worden voornamelijk irritant gevonden. De reden hiervoor is gedeeltelijk inhoudelijk, maar worden nog meer bepaald door de afzender en inzetfrequentie (veel van deze commercials zijn simpelweg te vaak op TV). Ook hier is onduidelijk hoe efficiënt deze commercials zijn? Waarschijnlijk best goed, want ze zijn in ieder geval genoeg opgevallen zodat mensen ze nog weten te noemen tijdens de stemming. Aangezien dit door kijkers van een specifiek AvroTros programma gekozen wordt, kun je je afvragen hoe representatief deze selectie überhaupt is?
Waarom geen categorie met winnaars van Lampen en Esprix’s? Cannes Lions? En belangrijker, waarom geen subgroepen voor commercials met een vergelijkbare inzet of doelgroep? Stel dat ik een heel specifieke doelgroep heb (bijvoorbeeld kinderen) hoe wordt daar rekening mee gehouden?
Geduld is een schone zaak, maar ik heb zo’n vaag gevoel dat de voorspelling uitblijft. Jammer.
De honden blaffen, de karavaan trekt verder. We hebben het razend druk Coert, ondermeer met de verdubbeling van het aantal studies dit jaar. van eens per maand naar elke andere week, maar dat ter zijde. Laten we de draad oppakken.
Of Effies de beste uitmaat voor een effectiviteitsstudie zijn, kunnen we het zo over hebben. Maar laat ik hier voorop stellen dat wij in ieder geval een uitmaat hebben. Geen van de serieuze neuromarketingonderzoekers (misschien Nielsen uitgezonderd) heeft een uitmaat. Dus voorspel je niets. Alles wat je meet is relatief, een meter is een meter omdat we dat kunnen vergelijken en dus ijken met het origineel in Parijs. Dus mensen een EEG-setje opzetten en zeggen dat een commercial wel of niet werkt, die roepen maar wat vooral nonsens. Daarom hebben wij meer dan 200 scanuren geïnvesteerd in het bouwen van benchmarks.
Voor effectiviteit hebben we Effies gebruikt, maar alleen dié van de categorie kortlopend dus sales. Deze meting krijgt pas waarde als je het totaal weer vergelijkt met iets anders. Daartoe hebben we Gouden Loekies GL en Loden Leeuwen LL genomen. Publieksprijzen die met stemming tot stand zijn gekomen en dus door het aantal stemmen betrouwbaar wordt. Vervolgens hebben we de uitkomsten vergeleken met de literatuur van wetenschappelijke MRI-studies naar gedrag, beslissingen en zelfs aanschaf van producten terwijl men in de scanner ligt. Onze uitkomsten komen overeen met die van de wetenschap. Mijn partner professor lamme heeft daar in 2013 al over gepubliceerd. Door de jaren heen is de benchmark verbeterd en verfijnd. En hebben in de praktijk bewezen dat de voorspellingen van koopintentie veel betrouwbaarder zijn dan de ‘onderbuik’ van de (gemiddelde) marketeer of zijn/haar adviseurs. Zo simpel is het Coert. Dus de GL en LL hebben we gebruikt om de campagnes te kunnen classificeren. Neemt niet weg dat ze een eigen categorie vormen. En ja, soms zijn LL ook effectief. En soms zijn LL ook likable.
ECHTER: een Effie is een algemene maat. Veel beter is het om van één specifieke klant één specifieke benchmark te ontwikkelen die dan ook alleen voor dat ene merk relevant is. Dat kan zijn voor sales, of juist voor het merk (lange(re) termijn) Dit zie je langzaamaan gebeuren. Zelf doen we ook intensief studie naar de werking van merken in onderbewuste.
Waarom geen categorie met winnaars van Lampen en Esprix’s? Cannes Lions, vraag jij je af. Een aantal van deze zit automatisch in LL of Effies. Zoals in het begin van onze studies Pietertje van Calvé. We testen voor onszelf de Super bowls bijvoorbeeld of de recente kerstcommercials De SB’s scoren vooral op likability mag je verwachten. En als het gaat om sales was de AH-kerscommercial by far de beste; en lijk dan ff naar de omzetten van die supers.
Oh ja., mensen zijn verschillend. Niet hoe we beslissen (nature) maar waarover we beslissen (nurture). Dus scannen we ook subdoelgroepen. We hebben nog eens 24 oncologen in de scanner gehad. En zelf radiologen, de voor het eerst van hun leven in hun ‘eigen’ apparaat lagen. Daarmee moet je dus rekening houden. Dat doen we natuurijk ook, we (onze wetenschappers) zijn niet gek. Maar belangrijker is dat we willen leren Coert, en er is nog heel veel te leren. En daar gaat het om. Alles wat een mens doet ontstaat in het brein. Daar moet je willen kijken. Open staan voor veranderingen en niet zomaar roepen dat iets goed is, omdat het goed is. 80% van alle productintroducties flopt. En van de 20% die wel succesvol is kannibaliseert 60%!!!! ‘Do the math’.
“Ik gooi de helft van mijn budget weg, maar ik weet niet welke helft”, verzucht de marketeer. Onze klanten weten precies welke helft. En zijn hard op weg om die helft te halveren.
Hoi Martin,
Dank voor je antwoord. Er zit wel logica in wat je zegt, alleen niks wat ik zou kunnen verifiëren en ik ben bang dat we in die cirkel vast blijven zitten, want ik snap ook wel dat je geen volledige openheid in je methodes en projecten kan geven.
Andries had het over de cover case, ik was benieuwd of daar mogelijk onderbouwing/data in zit die onafhankelijk getest kan worden.
“Onze klanten weten precies welke helft.”
Dat is nogal een uitspraak. Ben benieuwd hoeveel klanten van jullie dat openbaar willen onderschrijven?
Kijk.., er is natuurlijk geen groter bewijs van succes dan recurring business. En daar hebben we er gelukkig aardig wat van, anders waren we er na 8 jaar niet meer. En ja je begrijpt dat onze klanten niet met hun resultaten te koop lopen. Zelfs wij weten niet meer dan noodzakelijk. De cover case is al 7 jaar oud. Ik mag je wel wat successen laten zien, maar dat kan niet gedeeld worden, laat staan op Internet. Trouwens leg mij eens uit hoe je zo iets onafhankelijk zou willen testen? Wie anders doet commercieel MRI-scanning, ik bedoel serieus en betrouwbaar?
Getest was misschien niet het juiste woord, geverifieerd is beter. Een manier waarop de lezer zelf de conclusies uit de gepresenteerde data kan trekken.
Ik ben verder geen expert op het gebied van neuroscience, maar een concurrent van jullie gaf aan onder de indruk te zijn van Alpha.One.
Hi Coert. We hebben nog geen concurrenten omdat niemand structureel fMRI-onderzoek doet hahaha. Maar idd, de mensen van A1 weten waar ze mee bezig zijn en wat wel én niet kan met Neuro-onderzoek.
Gerelateerde artikelen
Marketingfacts. Elke dag vers. Mis niks!
Marketingfacts. Elke dag vers. Mis niks!