Sentimentanalyse: handmatig of automatisch?

Hoe verhoudt automatische sentimentanalyse zich tot handmatige analyse?
In social media analyses zijn we veelal op zoek naar de grootste criticasters en vanzelfsprekend de grootste enthousiastelingen van een merk, product, campagne of evenement. Om deze personen te vinden en vervolgens hun beweegredenen en argumenten te achterhalen, is het nodig om de verzamelde berichten in te delen in positieve, neutrale en negatieve berichten. Deze sentimentanalyses zijn een veelbesproken onderwerp. En er lijken twee kampen te zijn. Het ene kamp voert deze analyses met de hand uit. Het andere laat dit aan een computer over. Maar hoe verhoudt geautomatiseerd zich nu tot handmatige sentimentanalyse? Blauw Research en de Universiteit van Amsterdam sloegen de handen ineen en zochten het uit.
Sentiment is subjectief
Bij Blauw Research analyseren we in onze social media analyses berichten handmatig. Zo kunnen we de andere berichten die iemand plaatst er ook bij pakken en uit die context leiden we makkelijker het sentiment af. En om te checken of iemand iets ironisch bedoelt, moet je veelal de reacties van anderen op dat bericht zien. Zij kennen de afzender persoonlijk, en voelen ironie beter aan. Ook het perspectief waarmee we berichten van anderen bekijken is van invloed. Onderstaand bericht lijkt een negatief sentiment te hebben. Maar wat nu wanneer we een analyse doen voor de concertorganisator. Dan is het een uiting die aangeeft dat er zelfs nog meer mensen hadden willen komen en vanuit de organisator bezien dus positief.

Helpen computers?
Het kostenplaatje van handmatige analyse is wel een andere dan die van automatische analyse. Feit is dat niet iedere klant elke maand dat bedrag wil of kan uitgeven enkel aan de sentimentanalyse. Of dat het aantal berichten dat in sociale media verschijnt simpelweg te groot is om handmatig te doen. Wat wel geldt is: “garbage in, garbage out”. Wanneer de sentimentsaanduiding niet klopt, boeten de analyses die daarop volgen aan kracht in.
Het merendeel van de berichten die wij verzamelen over een merk, product of evenement is neutraal. Denk aan reclame, nieuwsberichtjes, locatieaanduidingen, etc. Deze neutrale berichten leren ons weinig. Juist de uitgesproken meningen zijn interessant. Wanneer geautomatiseerde routines ons kunnen helpen een groot aantal neutrale berichten al bij voorbaat te filteren, dan kunnen we daarna sneller handmatig de positieve en negatieve berichten analyseren. Om te kijken wat we hiermee kunnen hebben we samenwerking gezocht met studenten kunstmatige intelligentie van de Universiteit van Amsterdam. De afgelopen twee maanden hebben 25 tweedejaars studenten in groepjes hun best gedaan om de computer net zo ‘slim’ te maken als onze analisten. Zij hadden 10.000 berichten tot hun beschikking waar wij reeds handmatig een sentimentsaanduiding aan hadden toegekend. De opdracht was simpel: kijk of het lukt om de computer dezelfde sentimentsaanduidingen toe te laten kennen aan de berichten.
De studenten hebben een groot aantal complexe methoden toegepast (voor de kenners: variërend van Support Vector Machine, Naive Bayes Classifier, Neurale netwerken, weighted sum, etc.). Al deze methoden werken door te tellen hoe vaak bepaalde woorden of combinaties van woorden (n-grams) voorkomen in de berichten. En vervolgens te kijken of het aanwezig zijn van die (combinatie van) woorden voorspellende waarde heeft voor het sentiment van dat bericht. Heel simpel: wanneer het woord “groen” even vaak voorkomt (relatief) in de negatieve, neutrale en positieve berichten dan kan dat woord niet gebruikt worden om het sentiment van dat bericht te bepalen. Deze werkwijze houdt ook in dat er een trainingset nodig is om de algoritmes te vormen. Het sentiment in deze trainingset wordt zo goed mogelijk gemodelleerd waarna gekeken wordt hoe goed het sentiment van nieuwe berichten voorspeld kan worden.
Wat was het resultaat?
Het gaat te ver om de resultaten te bespreken van alle groepjes. Het belangrijkste wat ik echter wil delen, is dat we nu voor het eerst goed zicht hebben op hoe geautomatiseerde sentimentanalyse zich verhoudt tot handmatige analyse. Van de originele 10.000 berichten waren er volgens onze handmatige inschatting 2.500 met sentiment en 7.500 neutraal (1:3). Wanneer je de computer sentiment toe laat wijzen, worden er op twee manieren fouten gemaakt: berichten die volgens de handmatig inschatting neutraal zijn, worden door de computer verondersteld sentiment te bevatten en andersom, berichten die handmatig als sentiment bevattend worden beoordeeld worden door de computer neutraal geacht. De tweede fout, waarbij een klacht of compliment over het hoofd wordt gezien is eigenlijk erger, want hier wordt informatie gemist.
In onderstaande tabel staan de resultaten vermeld:
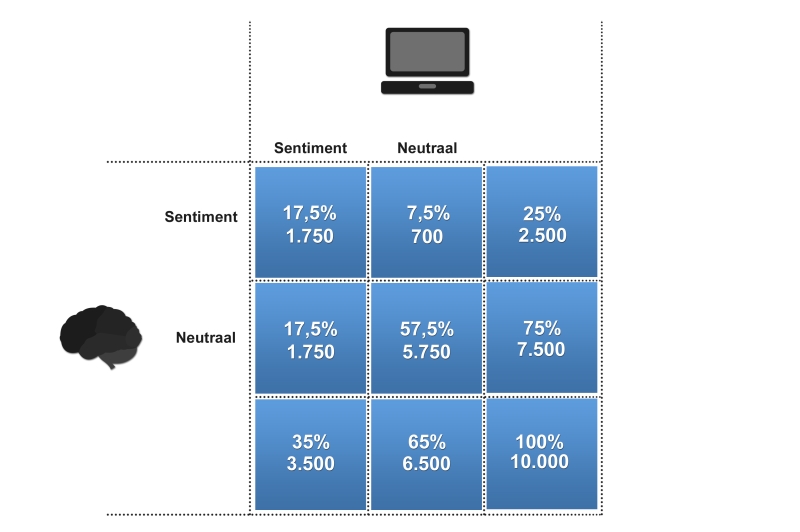
Wat valt op?
-
In totaal wordt 75% van de berichten juist geclassificeerd (17,5% + 57,5%).Ter referentie: wanneer de computer naïef zou zeggen dat alle berichten neutraal zijn, zou ook 75% van de berichten juist geclassificeerd zijn. Gelukkig zit de winst er in dat ook berichten met sentiment juist geclassificeerd worden.
-
De computer overschat het aantal berichten met sentiment. In plaats van een kwart, denkt de computer dat ruim een derde (35%) van de berichten sentiment bevat.
-
De ene fout, het bericht is volgens onze analisten neutraal, maar volgens de computer bevat het sentiment, wordt (mede door het vorige opvallende resultaat), veel vaker gemaakt dan de andere foutsoort (17,5% vs 7,5%).
-
De computer slaagt er iets beter in neutrale berichten te identificeren. Iets meer dan driekwart (57,5% / 75%) van de neutrale berichten wordt door de computer correct als neutraal geclassificeerd ten opzichte van 70% van de berichten met sentiment.
Hoe kun je dit toepassen?
De computer alles laten classificeren lijkt, op basis van deze resultaten, geen goed idee. Uiteindelijk is dan een kwart van je berichten voorzien van een verkeerde sentimentaanduiding. Maar er is tijdwinst te behalen wanneer je de computer een deel van het voorwerk laat doen. Stel, je filtert alle volgens de computer neutrale berichten uit je set berichten. Dan blijft een set berichten over waarin de verhouding sentiment/neutraal opeens 1:1 is (was 1:3). Dus 1 op de 2 berichten heeft opeens een uitgesproken mening. De set berichten is aanzienlijk verkleind en vervolgens kan je van één op de twee berichten wat leren. Een aanzienlijke tijdwinst, maar wel eentje met een prijs. Niet alle berichten die neutraal worden verondersteld door de computer, zijn dat ook echt. Samen met de gefilterde neutrale berichten verdwijnt ook 30% van de berichten die wel sentiment hebben. Je gooit dus drie op de tien berichten met een positieve of negatieve mening mee weg.
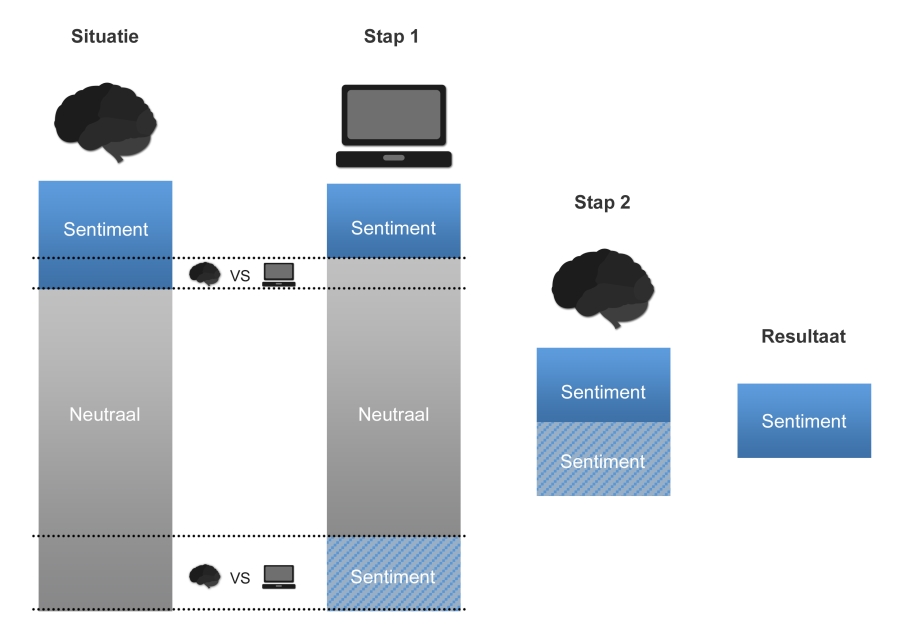
Bedenk ook dat er een aanzienlijke set berichten nodig is om de algoritmes te trainen. Wanneer je een nieuw merk of product gaat volgen, zal je nog steeds eerst een tijd handmatig moeten beginnen om zo een set berichten op te bouwen waarop de algoritmes ingericht kunnen worden. Je zou natuurlijk een set berichten over een heel ander onderwerp kunnen gebruiken, maar dan kan je geen rekening houden met de nuances die dit specifieke merk of product met zich meenemen.
En nu?
Goede vraag. Ik weet het niet zo goed. Ik blijf er bij dat je het maximale uit een social media analyse kan halen wanneer je dit volledig met good old handwerk aanpakt. Maar ik wil ook klanten met een kleiner budget of hele grote hoeveelheden berichten kunnen bedienen. En de tijdwinst heeft op zichzelf ook een ‘prijs’. Er glippen berichten met sentiment door de mazen van het net. Zodoende is geautomatiseerde sentimentbepaling ook minder bruikbaar voor webcare doeleinden. Want kan je het je veroorloven om drie op de tien klanten met een vraag of klacht te negeren? Hoe denken jullie er over? Verrassen de resultaten jullie?
We gaan hier zeker een vervolg aan geven want de studenten en wij zien nog veel ruimte voor verbetering. Kan je bijvoorbeeld ironie modelleren? Wat gebeurt er als je alle berichten, die wij handmatig analyseren, blijft voeden aan een algoritme, wordt je black box dan steeds beter. Wat voor effect heeft het wanneer je niet woorden telt, maar juist probeert te begrijpen wat het bericht zelf betekent?
Ivo Langbroek is werkzaam bij Blauw Research als Innovation Officer. Hij is continu op zoek naar samenwerkingsverbanden waardoor Blauw slimme en mooie tools en methoden aan kan bieden aan haar klanten. Hierbij richt hij zich op informatieverzameling, -verwerking en -overdracht. Ivo heeft een passie voor 'alles met knopjes'. Momenteel hebben social media analyses, research communities en mobile research zijn bovengemiddelde interesse. Ivo is altijd in voor een goed gesprek over nieuwe technologie en onderzoek.
Hallo Ivo,
Goed stuk dat je hebt geschreven over het automatisch classificeren van het sentiment.
Wij hebben veel ervaring, een jaar of 8, met het automatisch herkennen van berichten zoals e-mail, sms of social media.
Voor Interpolis classificeren wij al de binnenkomende emailberichten met een gemiddeld percentage van 90% dat goed gaat. Hierin zit een mechanisme ingebouwd dat wanneer een bericht niet goed is geclassificeerd het bericht opnieuw getraind wordt (middels een handmatige actie)
Wij zijn op dit moment ook bezig met automatisch classificeren van social media berichten als uitbreiding van ons IQNOMY platform. Behalve dat we kijken of een bericht positie of negatief is kijken we of er koopsignalen in zitten, of het een vraag is, of iemand positief of negatief ingesteld is en we kijken naar de algehele stemming over een brand of organisatie. Dit alles realtime.
We maken hierbij gebruik van een trapsgewijs classificatiemodel.
Je geeft in je artikel aan dat het wellicht lang kan duren voordat je voldoende trainingsmateriaal hebt. Hiermee ben ik het niet eens aangezien een negatief of positief bericht niet afhankelijk is van het merk, bedrijf of product. Het gaat om de strekking van het bericht.
Je kunt heel eenvoudig socialmedia berichten gebruiken van andere bedrijven of merken zodat je snel een set hebt die groot genoeg is.
Wij zijn nu zelf bezig om een hele grote training set op te bouwen die voor iedere organisatie eenvoudig en snel ingezet kan worden
Zullen we een keer afspreken?
Rob Boeyink
Rob, Sven,
Dank voor jullie reacties! Fijn dat jullie het de moeite waard vinden.
@Sven, leuk artikel. Wij hebben Mechanical Turk-achtige opzet ook overwogen. Zag dat Crowdflower zelf ook opdrachten uitzet op Amazon Mturk. Heb zelf geen ervaring met de Google Predicition API. Wellicht andere lezers op MarketingFacts?
@Rob, ik spreek graag een keer af! Ben benieuwd naar jullie ervaringen, klinkt alsof jullie mooie resultaten boeken. Wellicht kunnen we een vervolg aan dit stuk geven door dezelfde berichten ook door jullie classificatiemodel te halen? Ik weet niet of ik het helemaal eens ben met je opmerking dat sentiment niet afhangt van merk, product of bedrijf. De classificatie van een bericht als “ik baal van mijn Volkwagen, heb liever een Toyota” is toch volledig afhankelijk van het doel van een analyse/het perspectief waarmee berichten bekeken wordt.
Ivo
Hey Ivo,
Ik heb je een bericht gestuurd via Linkedin zodat we een afspraak kunnen inplannen. Het lijkt me leuk en interessant om jullie berichten door onze clacifficatie tool te halen en dan de resultaten te publiceren.
Rob
Goed stuk, erg interessant en relevant. Naast het feit dat 1 op 4 berichten verkeerd wordt gecategoriseerd obv sentiment vs neutraal, is nog niet gekeken naar positief vs negatief sentiment. Ben ook benieuwd hoe groot de foutmarge computer vs mens is als we kijken naar codering in 3 categorieen ipv 2 (negatief + neutraal + positief). Bedankt voor de post Ivo!
Wim,
Dank! Het onderscheid tussen positief en negatief is ook naar gekeken. Echter, niet alle groepjes zijn hier aan toegekomen.
Wat opviel is dat een twee-traps opzet, waarbij de eerste classifier neutraal van sentiment onderscheidt en een tweede positief van negatief, beter werkt dan een classifier die in een keer de driedeling probeert te maken. De afweging sentiment/geen-sentiment en positief/negatief wordt dus door andere (gewichten aan bepaalde) woorden bepaald.
Een van de groepjes behaalde een score van 80% juist geclassificeerd ten opzichte van de handmatige inschatting bij het onderscheid tussen negatief en positief.
Wij werken overigens met een 5-punts schaal in de handmatige classificatie (zeer negatief, negatief, neutraal, positief, zeer positief). Reden om de uitersten van deze schaal te kiezen zijn bijvoorbeeld wanneer mensen anderen iets aanbevelen of juist afraden, d.w.z. wanneer getracht wordt een bepaalde mening over te dragen.
Een bericht als “ik vind zus en zo heel lekker” wordt positief geclassificeerd, een bericht als “probeer nu de nieuwe zus en zo, die is echt heel erg lekker” classificeren we als zeer positief. Op die manier vinden we makkelijker super- en antipromoters van een merk of product.
De studenten hebben om te beginnen de twee positieve categorieën bijeen genomen. Evenzo de twee typen negatieve berichten.
OK, dank voor deze toevoeging. Een score van 80% vanuit sentiment-berichten naar pos / neg is dan op zich niet eens heel gek gezien alle ironie & dubbele betekenissen die je daar kan hebben. Inderdaad goed om nog een iets verfijnder onderscheid te maken in sentiment met een vijfpuntsschaal.
Ha Ivo, Top artikel dit! Ik ben nog wel benieuwd hoe de handmatig geduide set is samengesteld. Wij hebben in het verleden geconstateerd dat natuurlijke personen het niet altijd eens zijn over het sentiment dat kan worden toegekend aan een bericht.
Hoi Michiel! Dank. Je hebt volkomen gelijk dat handmatige beoordelingen ook niet altijd even consistent zijn. Wij proberen dat zoveel mogelijk te bewerkstelligen door vaste analisten te koppelen aan een project. Een klein team analyseert de berichten van een bepaalde zoekopdracht (liefst maar 1 of 2 personen), zodat over tijd de berichten op eenzelfde manier beoordeeld worden. Fluctuaties in sentiment worden dan niet veroorzaakt doordat andere mensen de berichten zijn gaan beoordelen. Ook werken we met een codeframe waarin beschreven staat aan welke voorwaarden een bericht moet voldoen alvorens het een bepaalde classificatie verdient. De onderzoeker die op basis van de geclassificeerde berichten insights genereert fungeert als controleur. Wanneer hij/zij denkt dat een bericht verkeerd geïnterpreteerd is kan het bericht gecorrigeerd worden.
Interessante discussie. De discussie over handmatig tegenover automatisch is interessant maar ziet LexisNexis als aanvullend aan elkaar. Onze grote Europese klanten of zelf de top van het Nederlandse bedrijfsleven staan voor gigantische volumes artikelen of posts (of zelfs email) vaak in meerdere talen plus een combinatie van offline en online content. Handmatig is dan geen optie. Met een recall van 70% en 80% precisie leveren wij de best haalbare sentiment analyse. De output kan naar b.v. een grafische dashboard of een resultatenlijst. De communicatieprofessional bespaart dan een grote hoeveelheid werk en kan binnen die resultaten verder werken analyseren. Wij zien dit als aanvullend niet als vervangend.
Hoi Nick, Dank voor je bericht over de dienstverlening van LexisNexis. En indrukwekkende cijfers over de resultaten die jullie behalen. Wellicht kan je naast het resultaat nog wat meer vertellen over hoe jullie te werk gaan? Op jullie website lees ik dat jullie je vooral richten op invloedrijke blogs binnen social media. Monitoren jullie ook de kortere berichten op Twitter, Hyves en Facebook? Wij merken dat sentimentanalyse hier vaak wat lastiger is omdat mensen zich met minder woorden uitdrukken. Behalen jullie de genoemde recall en precisie ook bij deze bronnen?
Bedankt Ivo, wij monitoren ook microblogs zoals Twitter en de openbare delen van sociale platforms zoals Hyves en FB. Voor bijvoorbeeld een telecomprovider maken we van deze feeds een sentimentgrafiek. Het klopt dat doordat er relatief weinig woorden in microblogs staan we niet dezelfde resultaten halen als in een blog. Ik heb de cijfers daarvan niet paraat. Toch geeft het deze klant een globaal inzicht in het sentiment op deze specifieke social media over verschillende landen heen.
Het doel van mijn bijdrage aan de discussie was vooral te benadrukken dat handmatig en automatisch elkaar niet perse uitsluiten maar eerder aanvullen. LexisNexis pretendeert niet menselijke analyse te vervangen als het gaat om kwalitatieve analyse. Wij denken wel dat wij deze analysten een hoop tijd kunnen besparen als ze geconfronteerd worden met grote volumes door machinale tonaliteitsanalyse toe te passen en dan te finetunen met een human interface.
Dank voor je artikel. ik wil er graag twee opmerkingen bij maken.
De mogelijkheden voor de studenten om hogere precisie te behalen worden niet zozeer bepaald door de keuze van de classificatiestrategie als wel door de linguïstische analyse. Met n-grammen kun je veel, maar voor het vinden van sentimenten kom je snel op beperkingen. We hebben een proof of concept gemaakt waarin een diepere analyse plaatsvindt op basis van constraint grammar. Daarmee kunnen complexere en verder over de zin verspreide patronen worden herkend. Het is absoluut nodig om een dergelijk systeem toe te snijden op de specifieke organisatie of vraag.
Een ander, kleiner punt. In je verhaal ga je ervan uit dat de handmatige beoordeling 100% correct is. Gebruikelijk en beter is om te kijken hoezeer verschillende beoordelaars met elkaar overeenstemmen in hun oordeel. In veel praktische classificatiesituaties is dat ontluisterend weinig.
Hoi Theo,
Dank je voor je reactie! Je hebt absolut gelijk dat handmatige analyse ook niet een feilloze weergave is. Reden waarom wij met een classificatie-schema werken en steekproefsgewijze controles uitvoeren. Berichten handmatig tweemaal laten checken en vervolgens de berichten waar geen overeenstemming over is nogmaals bekijken zou heel mooi zijn, maar is in de praktijk helaas niet haalbaar.
Zou je het leuk vinden om eens verder te praten over jullie ervaringen?
Groeten Ivo
Gerelateerde artikelen
Marketingfacts. Elke dag vers. Mis niks!
Marketingfacts. Elke dag vers. Mis niks!