Multichannel conversie-attributie: de werkelijke bijdrage van advertentiekanalen effectiever meten

Adverteerders staan voor de steeds zwaardere opgave zorg te dragen voor het end-to-end-beheer van de customer journey, over kanalen en apparaten heen. Vanaf het eerste contactmoment via de uiteindelijke aanschaf tot onderhoud en service. Attributie-analyse speelt hierin een belangrijke rol.
Het doel van attributie is vast te stellen in welke mate en op welke wijze het contact van klanten met advertentie-uitingen van invloed is op de conversie. Het idee is dat een beter inzicht in de relatieve prestaties van bijvoorbeeld zoekmachine-advertenties, affiliatemarketing-programma’s en nieuwsbrieven én de wisselwerking tussen de verschillende advertentiemogelijkheden, adverteerders in staat stelt om hun budget doelgerichter te besteden.
Dat is echter makkelijker gezegd dan gedaan. Het is namelijk complexe materie, waarbij veel onbekende factoren een rol spelen. En gezien de toename van het aantal kanalen en apparaten dat bestaande en potentiële klanten voor hun beslissings- en aankooptraject gebruiken, zal het aantal onbekende factoren alleen maar toenemen.
Alleen al het beheer van gegevens werpt diverse vragen op:
- Rekenen we clicks en/of advertentie-impressies als contact?
- Welke tijdsperiode houden we aan voor een doorsnee aankoopcyclus bij het exporteren van gegevens?
- Kunnen we met cookies een zorgvuldige tracking doen op alle apparaten? En is het mogelijk om de customer journey daarmee volledig vast te leggen?
- In hoeverre kan de kloof tussen online en offline worden overbrugd?
- Wat is het beste model om de kanalen die klanten hebben gebruikt effectief van een conversiescore te voorzien?
Afbeelding 1: de customer journey vanaf het eerste contact met advertentie-uitingen tot het moment van aanschaf. Hoe relevant zijn de touchpoints? Hoe werken ze samen?

Afbeelding 2: een voorbeeld van een customer journey. Deze gaat bijvoorbeeld van start met het zelf invoeren van een URL. Daarop volgen vier e-mailcontacten, een contact via een verwijzende website, een nieuw e-mailcontact en tenslotte een contact via een zoekmachine wat uiteindelijk in een aankooptransactie resulteert. ‘Single touch’-modellen houden geen rekening met zoekmachine-advertenties, en evenmin met directe invoer van internetadressen. Ze brengen de customer journey onvolledig in kaart, omdat kanalen zoals e-mail compleet buiten beschouwing worden gelaten.
Klassieke attributiemodellen
In de praktijk wordt het meest gebruikgemaakt van eenvoudige heuristische modellen zoals ‘first touch’ en ‘last touch’. Ze leveren waar nodig vrijwel realtime resultaten en hun methodiek is eenvoudig te begrijpen.
Beide modellen wijzen een conversie op tamelijk eenvoudige wijze toe aan het kanaal waarmee een customer journey begon of werd afgesloten. Deze eenvoud brengt echter een nadeel met zich mee. De ‘single touch’-modellen laten de tussenliggende contactmomenten namelijk volledig buiten beschouwing, ondanks dat koopbeslissingen hierdoor mogelijk zijn beïnvloed.
‘Multi-touch’-modellen verdelen conversies over alle kanalen die daartoe hebben bijgedragen.
‘Multi-touch’-modellen ondervangen dit probleem. Ze verdelen conversies over alle kanalen die daartoe hebben bijgedragen.
In het eenvoudigste geval gebeurt dit evenredig. Als de customer journey bijvoorbeeld langs acht touchpoints voert, draagt elk kanaal bij aan 12,5 procent van het resultaat (8 x 12,5% = 100%).
Een evenredige verdeling is echter niet altijd realistisch en effectief. Aan de touchpoints die aan het begin en einde van een customer journey liggen, wordt vaak een hogere relevantie toegekend dan aan eventuele tussenstations. Dit soort verschillen wordt onder meer ondervangen door het positiegebaseerde model. Doorgaans krijgen het eerste en laatste touchpoint een gewicht van 40 procent toegekend. De resterende 20 procent wordt verdeeld over de tussenliggende, ondersteunende kanalen.
Er zijn echter ook alternatieve wegingsfactoren denkbaar.
In de praktijk worden nog meer benaderingen toegepast. Vaak gaat het om variaties op het op regels gebaseerde attributie-model, waarbij het model is aangepast aan persoonlijke voorkeuren. Het vervelende is dat dit soort subjectieve benaderingen zelfs een belangrijke rol kunnen spelen bij bijvoorbeeld de keuze van het basismodel of de definitie van de wegingsfactoren. Dat is niet bevorderlijk voor een optimaal resultaat.
Om marketingkanalen voor budgetdoeleinden op zakelijke en realistische wijze te scoren, zijn objectieve maatstaven nodig. Verder zou je een nog completer beeld kunnen krijgen als je ook customer journeys in je analyse meeneemt die níet tot een conversie leidden, terwijl de klassieke modellen deze buiten beschouwing laten.
Hierbij komen algoritmische en probabilistische methoden om de hoek kijken. Dat zijn termen die nogal ingewikkeld klinken. Dat dit soort methoden toch op begrijpelijke wijze kunnen worden toegepast, blijkt wel uit een berekening die in het kader van een onderzoeksproject werd voorgesteld. Daarbij werden vier shopping-datasets uit verschillende branches met in totaal meer dan drie miljoen customer journeys onderzocht.
Attributie volgens een op grafieken gebaseerde methode
Bij dit model staat een overgangsgrafiek respectievelijk een overgangsmatrix centraal (zie onderstaande afbeelding). Beide modelleren de waarschijnlijkheid van een wisseling tussen touchpoints tijdens de customer journey dan wel de overgang van een reeks touchpoints naar een andere reeks touchpoints. De grafiek geeft dit weer in de vorm van verbindingslijnen. De matrix geeft dit weer in de vorm van vermeldingen.
Alle stochastische gegevens kun je eenvoudig overnemen en in tabellen onderbrengen op basis van trajectdata die internetanalysetools (zoals Google Analytics) bieden.
Ter illustratie zijn vier customer journeys afgebeeld waarvan één geen succes opleverde:
- Search > e-mail > conversion
- Search > display > conversion
- Search > e-mail > display > conversion
- Social
Het globale conversiepercentage in de dataset bedraagt liefst 75 procent. Het eenvoudigste Markov-model, dat later aan bod komt, geeft de overgangen tussen de touchpoints als volgt aan:

Afbeelding 3: voorbeelden van een overgangsmatrix – grafieken voor vier customer journeys
Bij een representatieve customer journey-dataset ziet de overgangsgrafiek er als volgt uit:
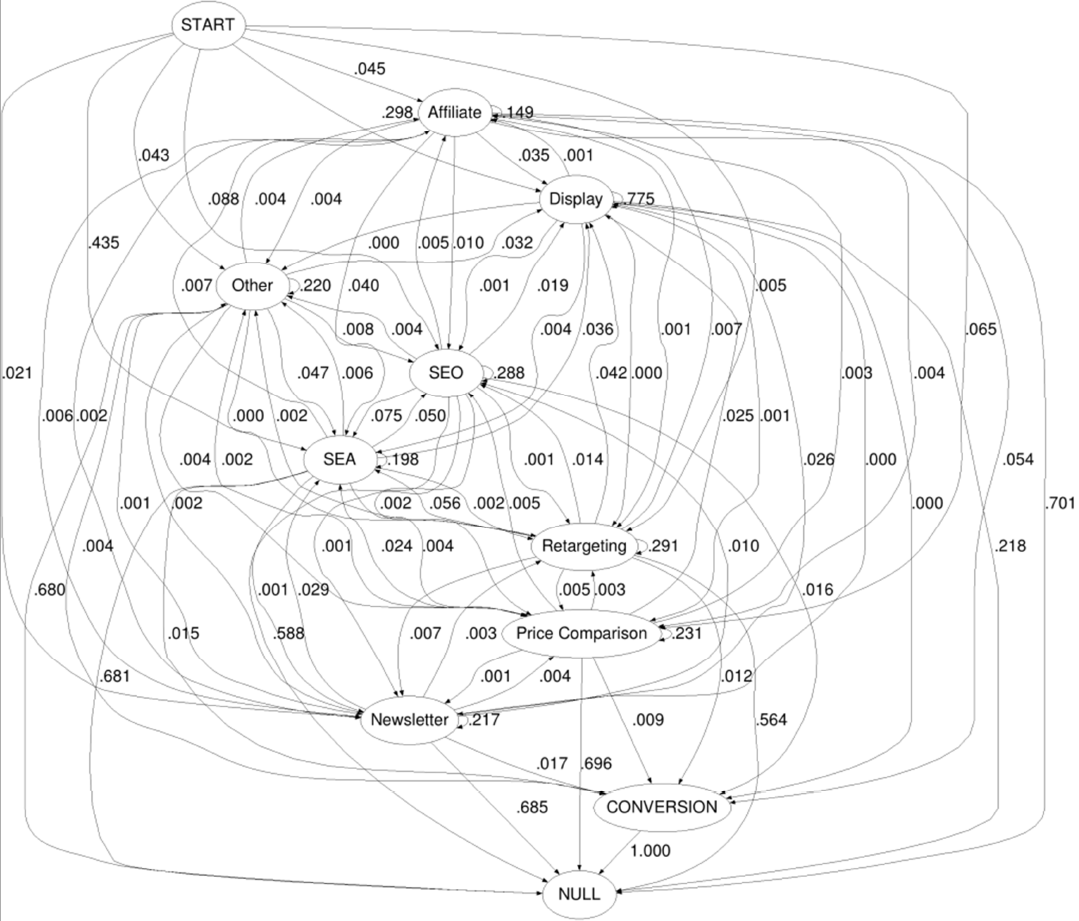
Afbeelding 4: complexer – de overgangsgrafiek van een eerste ordening voor een representatieve shopping-dataset
Overgangsmatrixen, zoals de matrix die boven de eerste grafiek wordt afgebeeld, leest men meestal regel voor regel, waarbij de som van elke regel 1 bedraagt. De waarschijnlijkheid dat het kanaal ‘e-mail’ (regel 4) bij de volgende stap in de customer journey naar ‘conversion’ (kolom 6) leidt, bedraagt daarmee 0,5 (= 50 procent).
‘Start’ en ‘null’ zijn als kunstmatige uitgangspunten aan het model toegevoegd. Daarbij toont start welke kanalen vaker de aanzet vormen tot een customer journey dan andere kanalen. Null vertegenwoordigt een soort modeltype eindtoestand die geen mogelijk vervolg kent, met of zonder conversie. De waarde op de diagonaal bedraagt hier 1 (= 100 procent), wat resulteert in een lus.
Beoordeling en interpretatie: e-mail wordt ondergewaardeerd
In alle shopping-datasets wezen de populaire attributiemodellen een te hoog succespercentage toe aan het kanaal ‘zoekmachine-adverteren’. Andere kanalen, zoals ‘e-mail’, werden daarentegen door het ‘last touch’-model en aanverwante benaderingen duidelijk ondergewaardeerd.
Removal effects als vergelijkingswaarden
Biedt een dergelijk model uitkomst voor attributie? Alleen als de waarde van het kanaal te berekenen is.
Een centrale vraag binnen marketingattributie is: wat zijn de juiste beslissingen op commercieel gebied? Alles draait in eerste instantie om de vraag hoe het reclamebudget juist wordt toebedeeld per kanaal. Hierbij komt het zogenaamde removal effect om de hoek kijken. Daarmee is het effect van de keuzes voor bepaalde kanalen weer te geven.
Het removal effect is een betrouwbare indicator en werkt vrij eenvoudig: door een kanaal volledig uit een grafiek te verwijderen, is het negatieve effect op de totale conversieratio de mate waarin dat specifieke kanaal bijdraagt aan de conversie. In extreme gevallen is het removal effect gelijk aan 100 procent van de totale conversieratio. In dit geval komt er zonder dit ene kanaal überhaupt geen conversie tot stand.
Dit model heeft een sterke voorspellende waarde en wordt berekend door het vermenigvuldigen van twee kansen:
- De kans dat vanuit het knooppunt ‘start’ een kanaal wordt bezocht.
- De kans dat vanuit het kanaal het punt ‘conversion’ wordt bereikt in plaats van het punt ‘null’.
Voor ‘search’ komt het removal effect in het bovenstaande scenario neer op 0,75 (= 0,75 x 1). Het staat daarmee gelijk aan het globale conversiepercentage: drie van de vier customer journeys resulteerden in conversie.
Deze situatie is direct zichtbaar in de grafiek: als men de lijn van ‘start’ naar het knooppunt search in de richting van het knooppunt ‘null’ zou ombuigen, zou er geen conversie tot stand komen. Het effect van ‘social’ daarentegen bedraagt 0 (= 0,25 x 0). Dit kanaal levert dus geen bijdrage aan de conversie. ‘Display’ en ‘e-mail’ komen elk uit op 0,5 (= 0,5 x 1).
Tenslotte is er bij deze analyse nog een stap die aan te bevelen is. Het aandeel van een effect op de som van alle removal effects, vermenigvuldigd met het totale aantal succesvolle conversies, resulteert in het totale aantal bereikte doelen die aan het desbetreffende kanaal kunnen worden toegeschreven. Zo is ‘search’ in theorie goed voor circa 42,86 procent (= 0,75 / (0,75 + 0,5 + 0,5)) van de in totaal drie conversies. Bij zowel ‘e-mail’ als ‘display’ ligt dit percentage op 28,57 procent.
Op deze manier kunnen de resultaten van het Markov-model met die van de heuristische aanpak worden vergeleken: relatief aan de hand van de aandeelpercentages of absoluut op basis van de over de kanalen verdeelde conversies. Hierbij stelden de onderzoekers duidelijke discrepanties vast tussen de resultaten van de algoritmische en op regels gebaseerde modellen…
Beoordeling en interpretatie: e-mail wordt ondergewaardeerd
In alle shopping-datasets wezen de populaire attributiemodellen een te hoog succespercentage toe aan het kanaal ‘zoekmachine-adverteren’. Andere kanalen als ‘e-mail’ werden daarentegen door het ‘last touch’-model en aanverwante benaderingen duidelijk ondergewaardeerd.
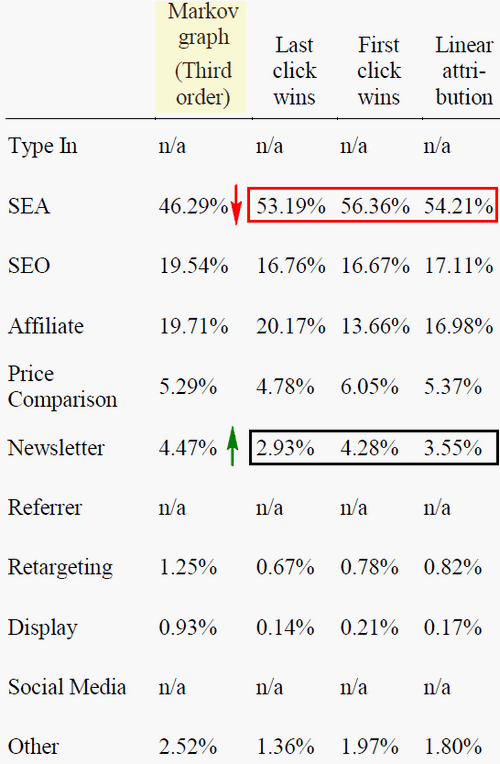
Afbeelding 5: derde ordening van het Markov-model (= kennis via de actuele en historische data van beide touchpoints) versus het ‘last touch’, ‘first touch’ en lineaire model – zoekmachine-adverteren’ wordt door op regels gebaseerde modellen overgewaardeerd, terwijl ‘e-mail’ en andere kanalen worden ondergewaardeerd.
De resultaten van een complexer model kunnen hier als vergelijkende waarden dienen. De complexiteit wordt gemeten aan de hand van hoever het model terugblikt binnen de customer journey.
In het simpelste geval (waarbij wordt gesproken van een ‘eerste ordening’ van het model) is alleen het huidige kanaal bekend. Alle waarschijnlijkheden zijn louter op dat ene kanaal gebaseerd. Bij hogere ordeningen wordt niet alleen gekeken naar het heden, maar ook naar het verleden. Bij het model van de tweede ordening hebben de overgangswaarschijnlijkheden betrekking op het huidige en het vorige touchpoint. Bij het model van de derde ordening hebben ze betrekking op hele reeksen van drie kanalen, enzovoort.
Modellen met een derde ordening aanzijn niet alleen nauwkeuriger, maar bieden ook het voordeel dat het samenspel tussen upstream en downstream kanalen kan worden onderzocht.
Hoe complexer, des te effectiever, maar dus ook ingewikkelder. Modellen met een hogere ordening laten zich makkelijk omzetten naar de eerste ordening. Daarbij stijgt het aantal model-knooppunten exponentieel. In dit kader raden de onderzoekers het gebruik van modellen tot maximaal een derde ordening aan. Deze zijn niet alleen nauwkeuriger, maar bieden ook het voordeel dat het samenspel tussen upstream en downstream kanalen kan worden onderzocht.
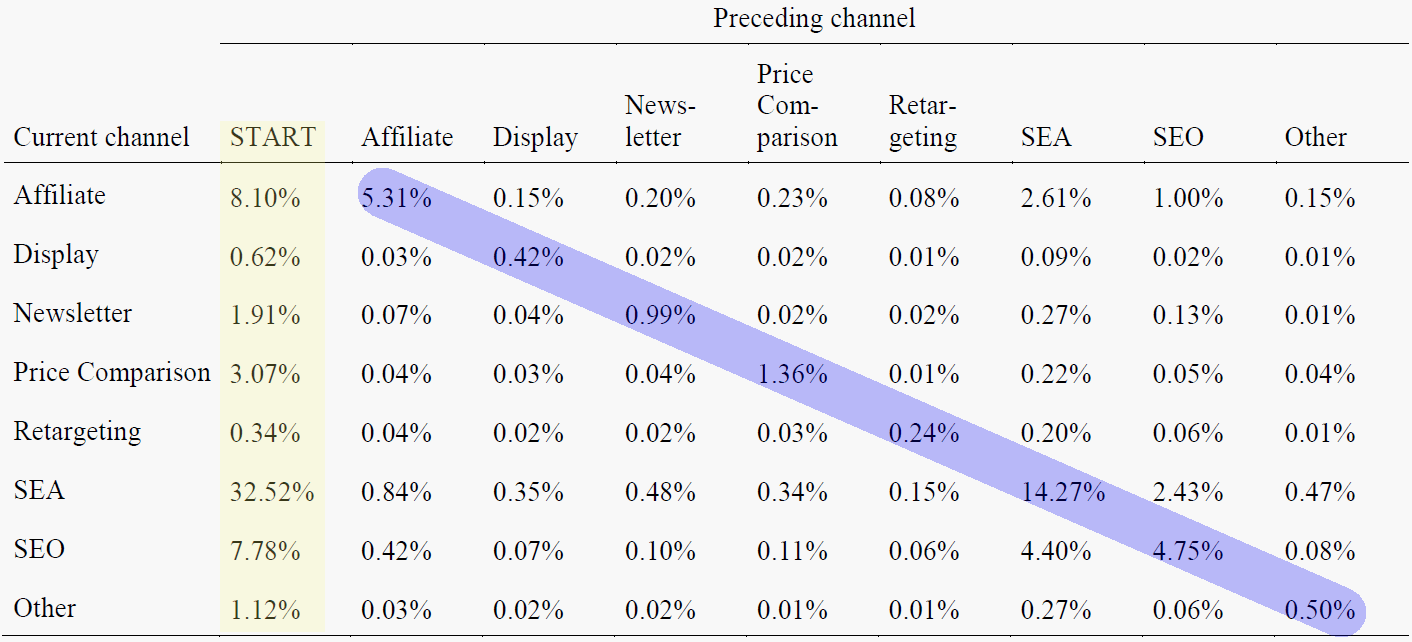
Afbeelding 6: attributie bij twee kanaalreeksen – het model van de tweede ordening maakt een analyse mogelijk van het samenspel van advertentiekanalen met voorbereidende kanalen
Het feit dat de ‘start’-toestand gezien de waarschijnlijkheid van het afsluiten van de customer journey het meest relevant is (kolom 1), is te wijten aan het grote aantal customer journeys met één stadium binnen de dataset. Daarnaast hebben achtereenvolgende contacten binnen hetzelfde kanaal vaak een zeer sterke uitwerking.
Het removal effect-aandeel van een e-mailcontact dat op een ander e-mailcontact volgt (kolom 4, regel 3) bedraagt bijna 1 procent, terwijl de effecten als andere kanalen zijn voorafgegaan (regel 3) slechts op 0,01 tot 0,27 procent uitkomen. Mogelijk weerspiegelt dit de kanaalvoorkeuren van een groot aantal gebruikers.
Conclusie
Het onderwerp multichannel attributie blijft boeiend. Het is interessant voor iedereen die klanten via meerdere advertentiekanalen wil aantrekken, zoals zoekmachine-advertenties, e-mailnieuwsbrieven en affiliatepartner-programma’s.
Het doel is een antwoord te krijgen op de vraag in welke mate deze individuele kanalen of het samenspel ervan bijdraagt aan de beoogde conversiepercentages. Want wie 1.000 euro aan zoekmachine-advertenties, e-mailmarketing en affiliate-programma’s uitgeeft en na drie maanden vaststelt dat de omzet daaruit 6.000, 3.500 of 500 euro bedraagt, zal in het volgende kwartaal zijn keuzes al dan niet heroverwegen.
Het is te kort door de bocht om de advertentiekanalen louter te meten op basis van het eerste of laatste contact in het kooptraject. Attributie moet waar mogelijk alle betrokken kanalen, dus ook de initiërende, ondersteunende en afsluitende kanalen, eerlijk beoordelen. Hiertoe stellen Anderl en zijn collega’s in hun whitepaper een algoritmische en objectiverende benadering voor, op basis van de Markov-keten, die in staat is grote aantallen customer journeys efficiënt te verwerken, of die nu wel of niet tot aanschaf hebben geleid. Dit kan een relevante aanvulling vormen op traditionele multitouch-modellen.
Feit blijft dat het meest complexe model niet automatisch het beste model is
Een relativerende kanttekening: feit blijft dat het meest complexe model niet automatisch het beste model is. Als de customer journeys uit niet veel meer bestaan dan een advertentiecontact met directe conversie, zouden de eerste simpele ‘first click’- en ‘last click’-regels al bevredigende resultaten moeten opleveren. De resultaten moeten ook altijd in het licht van de geldende randvoorwaarden worden gezien. Andere advertentiemiddelen of budgetbeperkingen per kanaal kunnen bijvoorbeeld heel andere resultaten opleveren.
Het idee een omvangrijke dataset snel en volledig op de beschreven manier te beoordelen heeft desondanks een zekere charme. Iets is beter dan niets. Als een beoordeling niet al bijdraagt aan het optimaliseren van de mediamix of het verbeteren van de klantrelaties, dan biedt een basisbeoordeling toch op zijn minst ondersteunende informatie bij de keuze voor het juiste traditionele attributie-model. Die laten zich immers al effectief vergelijken en analyseren met tools als de ‘Model Comparison Tool’ van Google Analytics. Deze tool maakt eenvoudige simulaties en vergelijkingen mogelijk.
Het is cruciaal de juiste, onderbouwde keuze voor een attributiemodel te maken. Wil je conversie-attributie naar een hoger niveau tillen, werk dan toe naar een diepgaander model. Maar wel één dat past bij de activiteiten, aard en customer journey binnen het bedrijf. En dat aansluit op het niveau van de marketingafdeling.
Meten is weten, maar alleen als je weet wat je moet doen met de resultaten.
René Kulka werkt als e-mailmarketing evangelist en consultant bij Optivo. Optivo is opgericht in Berlijn en is uitgegroeid tot één van de marktleiders in e-mailmarketing. Hij schrijft voor Optivo regelmatig over trends, praktische tips en marktontwikkelingen in de wereld van e-mailmarketing.
Thanks voor deze zware doorwrochte kost. ;>)
Stof tot nadenken, waarbij ik direct ook de metersdiepe kuilen zie om in te vallen.
Niet alleen de cross channel- maar juist de crossdevice- customer journey (70% naar sommige schattingen) gooit hier direkt, tav de meetbaarheid, een paar handen vol roet in het eten.
Deterministische tracking staat nog aan het begin en hier is nog vrij weinig data beschikbaar met name bij media distributie.
Tools als Google Analytics geven me dan weer de kriebels tav van een positieve bias richting SEA.
Meten is weten, maar weet ook dat je maar een deel meet!
Ik ben actief in de performnce based hoek en zie geregeld de discussies over ontdubbelingscripts. Waarbij niet enkel een optimalisatie van de ROI meespeeld, maar ook het feit dat, om je budget te kunnen balancen, je het makkelijkst kunt ontdubbelen op postpaid kanalen.
Ik wil niet ondankbar overkomen over je fraaie artikel. Ik zie zeker een opsteker in het feit dat affiliate, na SEA het hoogste succespercentage heeft.