Google zoekvolumes betere voorspeller dan social media-monitoring

Anderhalf uur voordat de eerste stemmen voor de Amerikaanse presidentsverkiezingen waren geteld, riep ik dat Obama 'met twee vingers in de neus' ging winnen. Niks too close to call – zoals organisatoren van polls, journalisten en deskundologen verwachtten. Nee hoor, een afgetekende overwinning. En daar kwam geen onderbuikgevoel of glazen bol aan te pas. Wel dit: een simpele analyse van zoekvolumes in Google met behulp van Google Trends.
Swing states
In de voorspelde nek-aan-nek race tussen Obama en Romney zouden de zogenaamde swing states doorslaggevend zijn. Dat stond wel vast. De strijd ging eigenlijk slechts om negen staten: Ohio, Florida, North Carolina, Virginia, Iowa, Colorado, Nevada, Wisconsin en New Hampshire.
In Google Trends vergeleek ik enkele uren voordat de eerste uitslagen bekend werden de Google-zoekvolumes voor Obama en Romney. Vervolgens beperkte ik de periode tot 'afgelopen dertig dagen' en zoomde ik één voor één in op die negen swing states. Voor het gemak van de analyse exporteerde ik de resultaten (csv-bestandje) en maakte ik uiteindelijk deze charts.
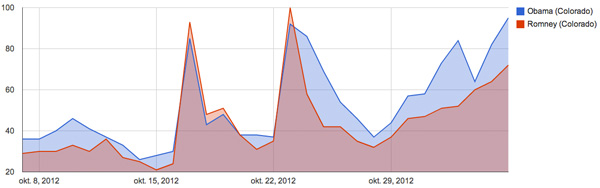
Zoekvolumes op “Obama” vs “Romney” in de staat Colorado. Klik op de afbeelding voor grafieken van alle swing states.
Zoals je in de grafieken terugziet, was het zoekvolume voor Obama in alle negen swing states vlak voor de verkiezingen (aanzienlijk) groter dan het zoekvolume voor Romney. En omdat ik al dikwijls heb gezien en ervaren hoe krachtig de voorspellende waarde van zulke verschillen in zoekvolumes is, durfde ik gerust een grote broek aan te trekken op Twitter:
#AmerikaKiest Obama wint dik als Google-zoekvolume een goede voorspeller is. Zie mijn analyse van swing states.bit.ly/TIZDaH
— Marcel Maassen (@MarcelMaassen) November 6, 2012
Krachtig, maar niet onfeilbaar
Het zoekvolume zegt 'iets' over interesse, niet per se over voorkeuren. Nederlanders die massaal naar Joran van der Sloot zoeken, hebben geen voorkeur voor hem, maar ze zijn wel in hem geïnteresseerd. Het feit dat Obama in Ohio meer zoekvolume had dan Romney, was dus zeker geen harde voorspeller van voorgenomen stemgedrag. Het toonde daarentegen wel degelijk aan, dat hij meer 'top of mind' was.
Google Trends is zeker geen onfeilbaar onderzoeksinstrument. Dat blijkt bijvoorbeeld wel als we de zoekvolumes bekijken in de staat Wyoming. Romney won daar met grote afstand (69,3% versus 28% voor Obama), maar vlak voor de verkiezingen zochten mensen in Wyoming toch meer naar Obama. In de dertig dagen voor de verkiezingen oversteeg het zoekvolume voor winnaar Romney bovendien bijna nooit het zoekvolume voor Obama.
Je kunt dus zeker niet blind varen op Google Trends-analyses. Je ziet slechts dat iemand íets zoekt, niet waaróm hij of zij dat zoekt. Conclusies verbinden aan slechts één vergelijking is heikel. Bij een vermoeden van een trend is het raadzaam verder te zoeken naar zoekvolumedata die dat vermoeden versterken of ontkrachten.
De naam 'Google Trends' is trouwens ook goed gekozen. Want trends, dat is inderdaad wat je ziet, geen harde cijfers. De redactie van Marketingfacts vroeg mij of ik ook een verband kon ontdekken tussen de verschillen in zoekvolumes en de verschillen in binnengehaalde stemmen. Nee, dat kan ik niet. Want in Florida bijvoorbeeld, de swing state met het kleinste verschil in stemmen, is het verschil in zoekvolume tussen Obama en Romney beduidend groter dan in andere swing states.
Anders dan social media monitoring
Toen Obama vier jaar geleden voor 't eerst werd gekozen, was ik (voor TNS NIPO) vooral druk met social media-monitoring rondom die verkiezingen. Voorafgaand aan de Nederlandse verkiezingen van 2010 onderzocht ik in opdracht van een grote politieke partij ook een jaar lang de social media-conversaties. En hoewel dat vele bruikbare en verrassende inhoudelijke inzichten opleverde, ben ik er nooit ook maar bij benadering in geslaagd een stembusuitslag te voorspellen.
Het tellen van mentions in social media geeft gewoon een scheef beeld dat met geen mogelijkheid meer recht te trekken valt. Je meet immers alleen uitspraken van degenen die zich roeren in het online debat, en dat is niet per se – beter gezegd: per se niet – een representatieve afspiegeling van de hele polulatie. En daar komt het nagenoeg onoplosbare sentiment-probleem bovenop. Ik ben gaandeweg zo intens moe geworden van al die aanbieders van monitorplatformen die durven beweren dat ze sentiment automatisch kunnen detecteren. Mannen: de komende driehonderd jaar gaat jullie dat niet lukken!
Het onderzoeken van zoekvolumes is vele malen simpeler. Je kan er maar één ding mee, maar dat ding gaat wel vaak goed. Want met zoekvolume-onderzoek meet je wel degelijk de interesse van een zeer groot deel van de populatie. Bovendien is het volmaakt eenduidig: zoeken ze op Obama, ja of nee? Daar komt geen interpretatie of (verkeerd) opschonen van data aan te pas. Het is wat het is.
Wat kan de business ermee?
Dit voorbeeld spreekt boekdelen. Op 29 december 2011 stond het bericht Verkoop Playstation Vita daalt hard op NU.nl. “De Playstation Vita is in zijn tweede week op de Japanse markt 78 procent slechter verkocht dan in zijn eerste week”, lazen we. Die tweede week waarin de verkoop hard inzakte, begon op 19 december. En zie hoe we dat al lang voor de publicatiedatum van dit bericht op 29 december hadden kunnen zien aan het zoekvolume:
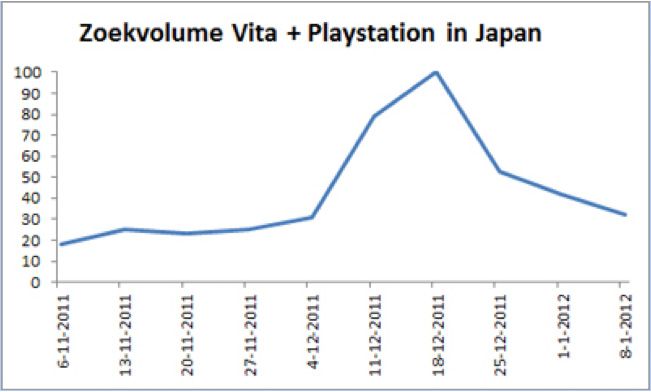
Met Google Trends hebben marktonderzoekers en marketeers een prachtige, simpele gratis tool in handen. Tot mijn verbazing maken ze er nog steeds nauwelijks of geen gebruik van.
Overigens pakte Google zelf rondom de Amerikaanse verkiezingen ook flink uit met zijn trends-analyses. Je vindt tal van voorbeelden op deze pagina.
Marcel Maassen is oprichter van Connectricity (online research & marketing)
Beste Marcel,
Zeer interessant artikel. Ik weet alleen niet helemaal of ik er in geloof, maar dat ligt niet aan jou. Bij het meten of monitoren van het internet, sociale media of zoekresultaten hangt alles af van timing, afspiegeling en sentiment. Dan zijn er nog externe factoren waar je geen invloed op hebt.
Voorbeeld:
Zet de zoekvolumes van de iPhone 5 eens af tegen die van de Galaxy S3. Dan zou je niet verwachten dat de verkoop van de iPhone 5 tegen vallen en Samsung topscoorder is met de S3. Hier spelen externe factoren als leverbaarheid mee.
Voorbeeld:
Hoeveel men ergens naar zoekt, zegt niets over het sentiment. Dat gaf je zelf ook al aan. Daarnaast kan een slimme marketingfiguur door een scoop te geven over dienst, product of persoon,extra zoekvolume genereren. Dat zien we ook wel bij virals. Goed voor branding, maar het zegt niet zo veel over de daadwerkelijke conversie.
Conclusie: Wachten op de uitslag geeft heet beste resultaat wat betreft monitoring. (grapje).
Beste Marcel,
Ik ga de komende tijd eens de resultaten van Google en Social Media naast elkaar leggen. Wie weet kom ik zo wel tot de (bijna) gouden formule. Bedankt voor je verduidelijking!
Ik heb nog een andere bedenking: zou het geen verband kunnen houden met het internetgebruik van democraten vs. de republikeinen. Het is geen onlogische redenering dat de democatisch kiezers een jongere en liberalere visie hebben, wat zich kan vertalen in een hoger internetgebruik en zoekgedrag, vergeleken met de ‘standaard-republikein’ ?
Hoi Marcel,
Dank je wel voor je interessante artikel. Interessant om eens een andere invalshoek te zien van online media monitoring.
Je opmerking over sentiment triggerde mij. Waarom ben je zo intens ( mooi woord ) moe geworden als het gaat over Sentiment analyse?
Hallo Martijn,
Alle aanbieders die pronken met automatische sentimentdetectie in hun monitoringplatform, gebruiken als basis lange woordenlijsten (positief en negatief). De gevonden documenten worden automatisch langs die woordenlijsten gehaald en het is dan simpelweg een kwestie van turven en tellen. Maar die woordenlijsten tellen toch echt maar duizenden woorden, terwijl de Nederlandse taal volgens een schatting van het Instituut voor Nederlandse Lexicologie één miljoen unieke woorden telt. Dat is exclusief in onbruik geraakte woorden en exclusief vervoegingen. Met die laatste erbij, loopt het aantal in de honderden miljoenen. En o ja, natuurlijk gebruiken we met z’n allen ook nog de gekste leenwoorden uit de gekste talen in onze posts.
Dit alles verklaart waarom in alle platformen zo’n tweederde van de documenten steevast als ‘neutraal’ wordt aangemerkt. In werkelijkheid zijn lang niet al die documenten neutraal van toon, maar schiet de matching eenvoudig tekort. Alleen de makkies halen ze er wel uit. ‘Klote Vodafone’, dat kaliber.
De eerste driehonderd jaar gaat echt betrouwbare automatische sentimentdetectie niet werken, schreef ik. Nou, laat ik er honderd jaar naast zitten, maar de uitdaging is werkelijk enorm. Er is immers ook nog zoiets als de ’toon’ van een tekst. Zonder ook maar een enkele expliciete diskwalificatie kan een auteur toch buitengewoon negatief zijn over een aanbieder of een product. En er is ook zoiets als context. Woorden hebben lang niet altijd de eenduidige betekenis die ze volgens het woordenboek zouden moeten hebben. Met een enkel voorvoegsel kan een woord plots het tegenovergestelde gaan beteken. En ironie, niet te vergeten. Als iemand ‘mooi man’ schrijft terwijl hij juist het tegenovergestelde bedoelt, dan is er geen computer ter wereld die dat uit de context kan opmaken.
Het is geen schande, dat automatische sentimentdetectie nog niet werkt zoals we zouden willen. Het is wel een schande, dat nagenoeg alle aanbieders doen alsof hun neus bloedt. Kopers laten zich ondertussen in de luren leggen met spiegeltjes en kraaltjes. Prachtig dashboard, schitterend! Maar ik snap dat wel: cijfers kosten veel minder tijd dan letters. Het is toch schitterend dat je in één oogopslag ziet dat 13,5 procent van alle berichten op Twitter positief zijn over je merk. Dat is +0,6 ten opzichte van Q2. Toppie!
Gerelateerde artikelen
Marketingfacts. Elke dag vers. Mis niks!
Marketingfacts. Elke dag vers. Mis niks!